간만에 생활코딩 하나.
아이가 다니는 유치원이 문을 닫는다고 해서 혹시나 아이들 활동 사진을 올려주는 카페도 닫을까봐 부랴부랴 크롤러를 만들기 시작했다. 지금은 내년 2월까지는 운영하기로 합의된 상태지만.
사실 올 해 중순 쯤부터 생각했던 건데, 우리뿐 아니라 딸아이 친구들네도 받을 수 있게 웹 인터페이스로 제공하고 싶었다. AWS에다가 내가 여전히 잘 모르는 인증을 붙여보고 누구든 자기 카페의 목록을 확인하고 그 안의 이미지를 받게 하면 되겠다는 생각이었다. 갑자기 문을 닫는다니 시간이 없어서 시도도 안해보고 다음 단계로 넘어갔다. 어차피 네이버 카페는 여전히 가입과 글 등록 이외의 API는 제공하지 않아서 크롤링을 하긴 해야 한다.
이때 가장 중요한 건,
빨리 만들어야 한다
손으로 일일이 다운로드 받는 것보다는 빨라야 한다(당시 사진이 1,000장에서 2,000장 쯤 되겠지라고 생각했기에 가능한 조건이랄까)
Laravel Dusk 급한대로 시도한 것은 standalone ChromeDriver를 사용하는 Laravel Dusk . 라라벨을 설치하고, Dusk도 추가.
composer create-project --prefer-dist laravel/laravel crawlincafe git init composer require --dev laravel/dusk:"^2.0" php artisan dusk:install
APP_URL을 네이버로 해주고
APP_URL=https://cafe.naver.com
dusk install할 때 넣어주는 샘플 테스트를 돌려본다
❯ php artisan dusk PHPUnit 6.5.13 by Sebastian Bergmann and contributors. . 1 / 1 (100%) Time: 2.08 seconds, Memory: 12.00MB OK (1 test, 1 assertion)
유저 정보는 .env에 추가
USER_ID=네이버아이디 USER_PW=비밀번호
페이지 번호에 링크가 있으므로 페이징은 문제 없을 것 같고, 우선 로그인 후 원하는 페이지로 이동하는 실험을 해봤는데,
<?php namespace Tests \Browser ;use Tests \DuskTestCase ;use Laravel \Dusk \Browser ;class ExampleTest extends DuskTestCase public function testBasicExample ( { $this ->browse (function (Browser $browser ) { $userId = env ('USER_ID' ); $userPw = env ('USER_PW' ); $cafeId = env ('CAFE_ID' ); $browser ->visit ('https://nid.naver.com/nidlogin.login?mode=form&url=https%3A%2F%2Fcafe.naver.com%2F...' ) ->assertSee ('NAVER' ) ->assertSee ('로그인 상태 유지' ) ->type ('id' , $userId ) ->type ('pw' , $userPw ) ->press ('.login_form input[type=submit]' ) ->pause (5000 ) ->assertPathIs ("/{$cafeId} " ) ; }); } }
결과는,
이게 뭐야!
아마도 최근에 자동입력 방지 기능이 추가가 됐던 것 같다. 찾아보니 올해 여름쯤부터 나처럼 당황하신 분들이 여럿 보인다. pause를 주기도 하고, 여기저기 쓸데없는 클릭도 만들어보고, 마우스 drag 이벤트도 줘보고 했는데 잘 뚤리지 않아 빠른 포기.
역시 음식은 손맛 다시 분석을 시작했다. 이미지 URL만 있으면 별다른 인증없이 다운로드가 가능할까? 맞다. 이미지가 포함된 게시물까지 접근하는 게 문제지 이미지 URL만 확보되면 다운로드는 되는 거다. 그런데 PC버전의 경우, 아래와 같이 이미지 썸네일을 캔버스에 그려놓고 클릭을 하면 사진을 크게 보여주는 구조다.
엄청 불편하다. 그래서 모바일 버전으로 접근해서 URL을 수집하기로 했다.
2017년에는 5세반이라서 그런지 선생님이 정말 많이 올려주셨다. 총 80회(선생님 고맙습니다). 올해 6세반은 다 안 올라왔지만 졸업까지 약 40회 정도 올라올 것 같다. 회당 100장에서 400장 사이로 양이 엄청 많다. 난 도대체 왜 2천장이 안될 거라 생각했던가!
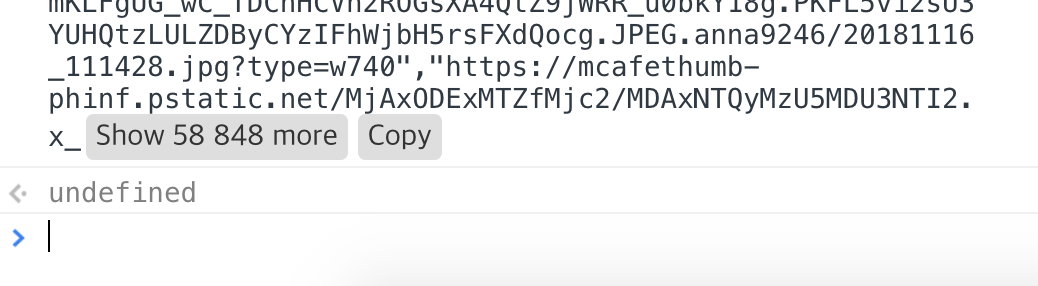
개발자도구를 열어놓고, 게시물 120건을 돌아다니며 이미지 URL을 수집했다. 수집하는 스크립트는,
(function ( let result = { "title" : document .querySelectorAll ('#ct h2.tit' )[0 ].innerText .replace (/[^0-9a-zAZㄱ-힣]/g , '_' ).replace (/__/g , '_' ).replace (/^_(.+)_$/ , "$1" ), "createdAt" : document .querySelectorAll ('#ct span.date' )[0 ].innerText .replace (/[^0-9]/g , '' ), "data" : [ ] }; document .querySelectorAll ('#postContent img.fx' ).forEach (function (item ) { result.data .push (item.src ); }); console .log (JSON .stringify (result)); })();
콘솔에 output할 양이 너무 많으면 콘솔 화면에 Copy 버튼이 생긴다.
다음 글로 이동 -> 개발자도구 클릭 -> 화살표 up key + enter -> Copy 버튼 클릭 Editor에 붙여넣기의 과정으로 120개 글에서 노가다를 좀 해줬다. 사실 중간에 한번 실수로 지워버린 바람에 160번은 한 것 같다.
더 쉬운 방법이 있진 않았을까 고민을 하긴 했었는데 당장 생각이 안나 머리를 덜 쓰는 방법을 택한 것. 목록 화면에서 개발자도구로 상세 화면을 불러와서 파싱해도 되지 않았을까 싶긴 한데. 이미 지난 일이니…
이걸 모아서 Guzzle로 다운로드 받는 프로그램을 후다닥 작성했다. 코드리뷰 해주실 필요는 없다. 유지보수 할 일 없고 빠르게 유용하게 잘 만들었으니 됐다.
<?php define ('PROJECT_ROOT' , '..' );require '../vendor/autoload.php' ;use GuzzleHttp \Client ;$targetDir = 'storage/data' ;$downloadDir = 'storage/downloads' ;if ($handle = opendir (PROJECT_ROOT . '/' . $targetDir )) { $data = []; while (false !== ($subDir = readdir ($handle ))) { if (strpos ($subDir , '.' ) === 0 ) { continue ; } $subDirPath = PROJECT_ROOT . '/' . $targetDir . '/' . $subDir ; if ($handleSub = opendir ($subDirPath )) { $data [$subDir ] = []; while (false !== ($file = readdir ($handleSub ))) { if (strpos ($file , '.' ) === 0 ) { continue ; } if (preg_replace ('/.+\.([a-z]+)$/' , '$1' , $file ) !== 'js' ) { continue ; } $fileTxt = file_get_contents ($subDirPath . '/' . $file ); try { $article = json_decode ($fileTxt , true ); } catch (Exception $e ) { echo 'json decode failed : ' . $subDirPath . '/' . $file ; continue ; } if (!empty ($article )) { $data [$subDir ][$article ['createdAt' ]] = $article ; } } closedir ($handleSub ); } } closedir ($handle ); } $client = new Client ([]); foreach ($data as $subDir => $articles ) { $subDirPath = PROJECT_ROOT . '/' . $downloadDir . '/' . $subDir ; if (!is_dir ($subDirPath )) { mkdir ($subDirPath ); } foreach ($articles as $createdAt => $article ) { $articleDirPath = PROJECT_ROOT . '/' . $downloadDir . '/' . $subDir . '/' . $article ['createdAt' ] . ' - ' . $article ['title' ]; if (!is_dir ($articleDirPath )) { mkdir ($articleDirPath ); } echo $articleDirPath . PHP_EOL; foreach ($article ['data' ] as $index => $imageUrl ) { $filename = str_pad ($index , 3 , "0" , STR_PAD_LEFT) . '.jpg' ; if (file_exists ($articleDirPath . '/' . $filename )) { continue ; } try { $client ->request ('GET' , $imageUrl , ['sink' => $articleDirPath . '/' . $filename ]); } catch (Exception $e ) { echo PHP_EOL . $e ->getMessage () . PHP_EOL; } echo '.' ; usleep (100 ); } echo PHP_EOL; } }