6월 말에 개발과 관련없는 책을 읽어보려고 집어왔던 책. 올해 8월 제천 영화제에 들고가서 조금 읽고 왔던 책.
그 당시 감상으로 ‘좌파 교수(좋은 의미로)가 쓴 책’ 정도로 이야기 했지만, 그건 정말 초반에 (의도는 좋지만 = 선하지만) 재미가 없어서 했던 말이었다.
이번에 날씨가 너무 좋아 점심시간에 책보러 카페로, 작은 공원(?)으로 다니며 읽었는데, 이번엔 또 너무 재미있는 거다.
책은 세 챕터로 나뉘는데,
‘지금 여기’를 말하는 사회물리학의 세계
복잡한 세상을 꿰뚫어 보는 통계물리학의 아름다움
물리학자는 세상물정을 모른다고?
두번째 챕터부터 신나게 읽었던 것 같다.
작은 호기심을 증명해내고야 마는 집념. 이전에 읽었던 책 ‘아이의 사생활’에 비해 근거로 충만하고 같이 실험했던 사람들의 이름도 꼬박꼬박 넣어주는 친절함. 은근 코드가 맞는 개그감. 최대한 이해하기 쉽게 설명하는 물리 개념. 그리고 과학자로서의 열정과 자부심을 드러내는 지점에선 일부 공감과 반성을 하곤 했었다.
글을 굉장히 잘 쓰신다. 요즘 나는 기술책만 너무 많이 보다 눈높이가 꽤 낮아진 관계로… 문학을 즐기는 분들이 보기엔 어떨지 모르겠다. 하지만 (과연 이게 칭찬이 될 지는 모르겠지만) 이공계 중에선 수준급이다!
Character references should always start with a U+0026 AMPERSAND character (&) and end with a U+003B SEMICOLON character (;).
문자 참조는 &로 시작하고 ;로 끝나야 한다.
Fun fact: the list of named character references in the HTML spec includes & and &, but also & and & (without the trailing semicolon). The same goes for a few other entities. This is done for backwards-compatibility reasons. This way, the spec dictates that foo & bar should be rendered as “foo & bar”, even though it’s invalid markup (because of the missing trailing semicolon). More on this in a minute…
재밌는 사실은: HTML 스펙에서 명명된 문자 참조는 &와 &를 포함하는데, 세미콜론(;)이 뒤에 붙지 않은 &와 &도 있다는 것이다. 다른 일부 엔티티도 마찬가지이다. 이건 하위 호환성을 때문에 이렇게 됐다. 이 방식으로, (세미콜론이 빠져있으면) 유효하지 않은 마크업임에도 불구하고, 스펙에선 “foo & bar”를 “foo & bar”로 랜더할 수 있게 지시하고 있다. 조금 이따가 다시 다루겠다.
In this post, we’ll take a closer look at what happens if there’s an unencoded ampersand that’s not part of a character reference in your HTML code. Is it valid? Is it invalid? And what do “ambiguous ampersands” have to do with all this?
이 포스트에선, HTML안에 지정된 문자 참조의 일부가 아니면서 인코드도 안 된 앰퍼샌드가 있을 때 어떤 일이 벌어지는 지 좀 더 자세히 살펴볼 것이다. 그게 유효한 문법인가? 아니면 유효하지 않은가? 모호한 앰퍼샌드는 이 모든 것과 어떤 관계가 있는가?
Unencoded ampersands in HTML4
인코딩되지 않은 앰퍼샌드
The HTML 4.01 spec mentions this:
HTML 4.01 스펙에서 이를 언급하기를:
The URI that is constructed when a form is submitted may be used as an anchor-style link (e.g., the href attribute for the <a> element). Unfortunately, the use of the & character to separate form fields interacts with its use in SGML attribute values to delimit character entity references. For example, to use the URI http://host/?x=1&y=2 as a linking URI, it must be written as <a href=”http://host/?x=1&y=2”> or <a href=”http://host/?x=1&y=2”>.
Form 전송 시 만들어지는 URI는 anchor 스타일 링크(예를 들어 a 엘리먼트의 href attribute)를 사용하게 된다. 불행히도, 폼 필드를 구분지으려고 &를 사용하는 것은, 문자 엔티티 참조를 위한 SGML(역주: HTML, XML등의 부모뻘 되는 언어) attribute 안에서 사용하는 것과 상호작용을 하게된다. 예를 들어, 링크를 위한 http://host/?x=1&y=2 이라는 URI는, 반드시 <a href=”http://host/?x=1&y=2”> 혹은 <a href=”http://host/?x=1&y=2”> 으로 쓰여야 한다.
This means you can’t just copy-paste URLs into your HTML4 document if you want it to be valid — you’ll have to encode any ampersand characters first.
이 말은 당신이 HTML4 문서에 URL을 단순히 복사-붙여넣기를 해서만은 유효하진 않을 거라는 의미이다 - 앰퍼샌드를 인코딩 해야할 거다.
Ambiguous ampersands in HTML5
HTML5에서의 모호한 앰퍼샌드
In HTML5, the first definition for ambiguous ampersands was added:
HTML5에서 모호한 ampersand에 대한 정의가 처음으로 추가됐다.
An ambiguous ampersand is a U+0026 AMPERSAND (&) character that is not the last character in the file, that is not followed by a space character, that is not followed by a start tag that has not been omitted, and that is not followed by another U+0026 AMPERSAND (&) character.
모호한 앰퍼샌드는 파일의 마지막 문자가 아니며, 공백 문자가 뒤이어 나오지 않고, 생략되지 않은 시작 태그가 뒤에 오지 않고 다른 앰퍼샌드 문자가 뒤따르지 않는다.
Ambiguous ampersands are non-conforming (invalid); unambiguous ampersands are generally conforming (valid). (As mentioned before: ampersands that are part of a named character reference that doesn’t end with a semicolon are unambiguous, but still invalid.)
모호한 앰퍼샌드는 …(역주: 번역하기 어려워 생략)…(이전에 언급한 것처럼: 세미콜론으로 끝나지 않는 명명된 문자 참조의 일부로써 앰퍼샌드는 모호하진 않지만, 아직 유효하진 않다.
In other words, if an unencoded ampersand is followed by EOF, a space character, <, or &, it’s perfectly valid.
다시 말해, 인코드 안 된 앰퍼샌드 뒤로 EOF, 공백문자, <, &가 있다면 이건 완전히 유효하다.
According to this definition, the ampersands in this example are all ambiguous, and thus invalid:
이 정의에 의하면, 아래 예시에서 모든 앰퍼샌드는 모호하고, 그러므로 유효하지 않다.
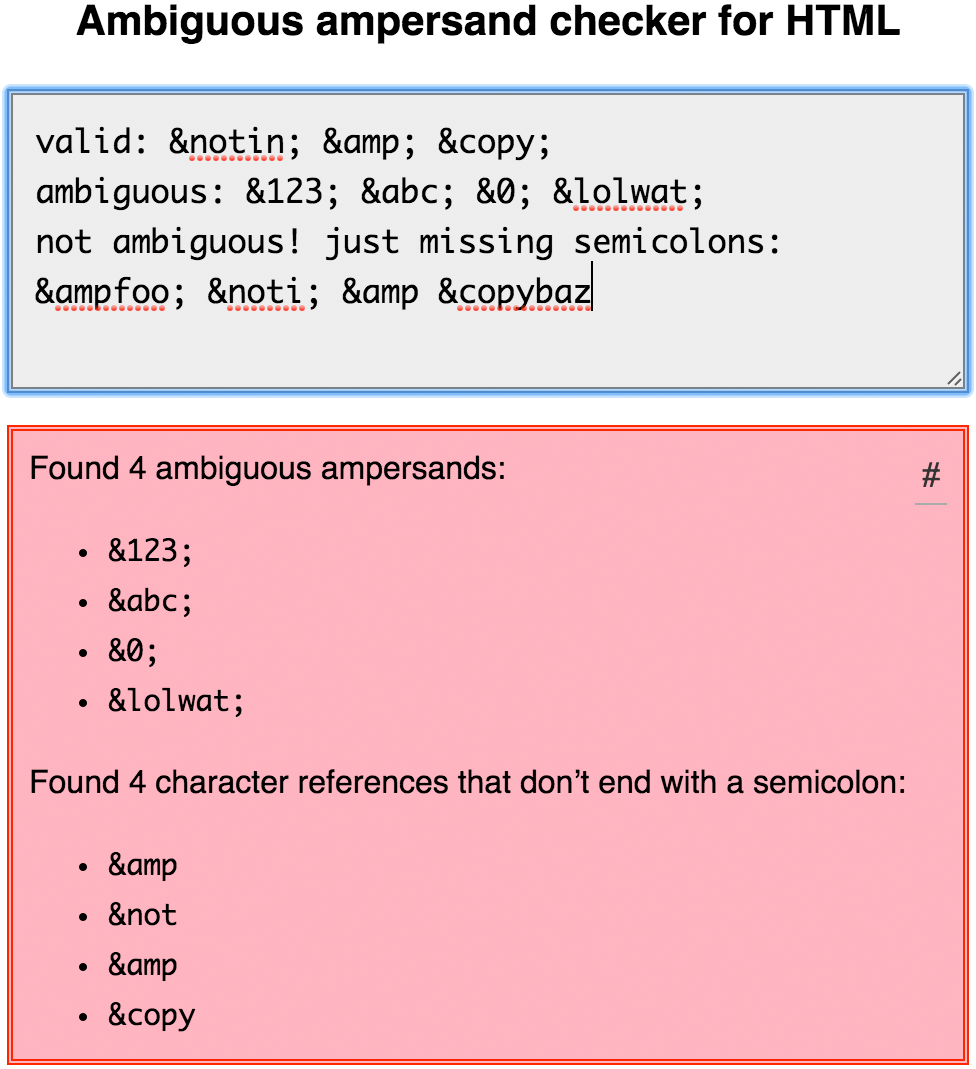
<a href="https://example.com/?x=1&y=2";>foo</a> &123 &abc foo &0 bar foo &lolwat bar
However, this is valid HTML:
그러나, 이건 또 유효한 HTML이다
foo & bar foo&<i>bar</i> foo&&& bar
Later the spec was changed, and the HTML spec now defines ambiguous ampersands as follows:
나중에 스펙은 수정되고 현재 HTML 스펙은 아래와 같이 정의되어 있다.
An ambiguous ampersand is a U+0026 AMPERSAND character (&) that is followed by one or more characters in the range U+0030 DIGIT ZERO (0) to U+0039 DIGIT NINE (9), U+0061 LATIN SMALL LETTER A to U+007A LATIN SMALL LETTER Z, and U+0041 LATIN CAPITAL LETTER A to U+005A LATIN CAPITAL LETTER Z, followed by a U+003B SEMICOLON character (;), where these characters do not match any of the names given in the named character references section.
모호한 앰퍼샌드는 하나 이상의 0~9 숫자, 대/소문자 라틴 문자와 세미콜론으로 이어지는 엠퍼샌드를 의미하고, 이 문자들은 명명된 문자 참조 영역에 있는 이름에 매칭되지 않는다.
This definition is probably easier to grok as a regular expression: a string contains an ambiguous ampersand if it matches /&([0-9a-zA-Z]+;)/ and if the first back-reference ($1) is not a known character reference.
이 정의는 아마 정규식으로 더 이해하기 쉬울 것 같다. 앰퍼샌드가 포함된 문자열이 /&([0-9a-zA-Z]+;)/ 에 매치되고, back-reference 된 값(역주: 정규식에서 괄호안에 매칭되는 값)이 알려진 문자 참조가 아니어야 한다.
The ampersands in this example are all ambiguous, and thus invalid:
아래 앰퍼샌드는 모두 모호하다. 따라서 유효한 문법이 아니다.
&123; &abc; foo &0; bar foo &lolwat; bar
However, all these are unambiguous:
그러나 아래는 모두 명확하다.
foo & bar foo&<i>bar</i> foo&&& bar
…even the ones that were invalid as per the old definition, are now valid:
…예전의 정의로는 유효하진 않지만, 현재 유효한 것은:
<a href="http://example.com/?x=1&y=2";>foo</a> &123 &abc foo &0 bar foo &lolwat bar
With the new definition, this is perfectly valid HTML — even though no HTML validator I know of recognizes this yet.
새로운 정의에 의해서는, 완벽하게 유효한 HTML이다 - HTML 유효성 검사기가 아직 이걸 모른다 하더라도 말이다.
So we’ve established that not all ampersand characters require escaping in HTML. Semi-related fun fact: In most cases, there’s no need to escape the > character either. It has no special meaning (and is thus unambiguous) unless it’s part of a tag or an unquoted attribute value. For example, <p>foo > bar</p> is perfectly valid and reliable HTML.
이제 우리는 HTML안에서 모든 앰퍼샌드가 escape 될 필요는 없다는 게 확실해졌다. 크게 관련은 없지만 재밌는 사실은: > 문자도 escape할 필요가 없다는 사실이다. 따옴표 없는 attribute값이나 태그의 일부가 아닌 이상 특수한 의미가 있지는 않다(모호하지 않음). 예를 들어, <p>foo > bar</p>는 완전히 유효하며 믿을만 한 HTML이다.
The pedantic nitty-gritty
학술적인 핵심
As mentioned before, some named character references work without a trailing semicolon (e.g. &) even though it’s invalid markup. What complicates things even more is that these entities are handled differently in attribute values.
말했지만, 일부 명명된 문자 참조는 세미콜론이 뒤에 붙지 않아도(그게 유효하지 않은 마크업 문법이라도) 동작한다. 이걸 더 복잡하게 만드는 건, 이 엔티티들이 attribute 값에서는 다르게 작동한다는 사실이다.
If the character reference is being consumed as part of an attribute, and the last character matched is not a U+003B SEMICOLON character (;), and the next character is either a U+003D EQUALS SIGN character (=) or an alphanumeric ASCII character, then, for historical reasons, all the characters that were matched after the U+0026 AMPERSAND character (&) must be unconsumed, and nothing is returned. However, if this next character is in fact a U+003D EQUALS SIGN character (=), then this is a parse error, because some legacy user agents will misinterpret the markup in those cases.
만약 문자 참조가 attribute안에서 사용되고 세미콜론으로 끝나지 않으며 다음 글자가 =나 알파벳, 숫자일 경우, 관행적으로, & 이후 매칭되는 모든 문자들은 처리되지 않고 아무것도 리턴되지 않는다. 그러나 이 ‘다음 문자’가 =이라면, parse error가 발생하는데, 오래된 user agent가 오역할 수 있기 때문이다.
Take this (obviously invalid) HTML, for example:
예를 들어, 명백히 유효하지 않은 다음 HTML을 보라
<p title="foo&bar"> foo&bar </p>
Try it out in your browser. You’ll see that the paragraph’s text content displays as “foo&bar”, while the titleattribute value is displayed as “foo&bar”.
네 브라우저에서 시도해봐라. 내용은 “foo&bar”라고 나오지만, title attribute 값은 foo&bar로 나올 것이다.
Mothereffing ambiguous ampersands
형편없는 모호한 앰퍼샌드
To summarize: there’s a difference between unencoded ampersands (sometimes valid), ambiguous ampersands (always invalid) and encoded ampersands (always valid). An unencoded ampersand is not always an ambiguous ampersand. An unambiguous ampersand can still be invalid.
요약하자면: 인코딩 안 된 앰퍼샌드(가끔 유효한), 모호한 앰퍼샌드(언제나 유효하지 않은), 그리고 인코딩된 앰퍼샌드(언제나 유효한) 사이에는 차이점이 있다. 인코딩이 안 된 앰퍼샌드가 항상 모호한 앰퍼샌드인 건 아니다. 모호하지 않은 앰퍼샌드도 여전히 유효하지 않을 수 있다.
In my opinion, this is all a bit confusing. But it doesn’t have to be! When in doubt, just encode your effin’ ampersands.
내 생각에, 이것들은 좀 헷갈린다. 하지만 그럴 필요는 없다! 의심스러우면, 망할 앰퍼샌드를 인코딩해라.
That said, if you want to find out if an HTML snippet contains any ambiguous ampersands or character references that don’t end with a semicolon (both of which are invalid), feel free to use mothereff.in/ampersands.
즉, HTML 스니펫에 모호한 앰퍼샌드나 세미콜론 (세미콜론으로 끝나지 않는 문자 참조)이 모두 포함되어 있는지 알아 보려면 (둘 다 유효하지 않음) mothereff.in/ampersands를 자유롭게 사용하기 바란다.
Note that this is not a complete HTML validator; it will only look for ambiguous ampersands and semicolon-free character references. (Hopefully, bug #841 will be fixed soon, so we can just rely on validator.nu instead.) Understanding what ambiguous ampersands are and how they work is especially important for library authors wishing to deal with HTML entities. Not accounting for these edge cases might result in XSS or other security vulnerabilities in your code.
책 자체가 잘 쓰였다고는 생각하지는 않다만, 부모로서 스스로 돌아보기에 괜찮은 기회일 수도 있다.
육아에 대해 큰 고민없이 살거나 고민은 많은데 부모 스스로 감정 조절이 안되거나 지금 내가 하는 게 맞나 싶은 사람이라면 도움이 될 수도 있겠다.
3장의 목차가 저 모양이라 마음엔 안 들지만 (오래 전 책이라 줄을 잘못 섰기도 섰거니와)
저 부분만 잘 넘어가면 이래저래 생각할 거리는 많다. (3장은 낯 간지러워서 도저히 못 읽겠다!)
한문장 한문장 읽으면서 내 행동을 돌아보는 용도로 가볍게 읽고 넘어가면 좋을 것 같다.
읽다보면 이 자존감을 세우는 일은 아이에만 필요한 게 아니다. 내 주위 사람들, 지나간 동료들도 많이 생각이 났다.
저기 자존감이 높은 대표적인 인물로 꼽힌 안철수가 그…(?) 과정을 거치며 얼마나 자존감이 낮아졌는가, 그 아이가 얼마나 삐뚤어졌나 생각해보자.
아쉬운 건, 이런 저런 연구 결과나 박사 이름을 언급하지만, 행동 지침을 도출하게 된 직접적인 근거는 또 아니어서, 이렇게 해라 저렇게 해라 하는 게 진짜 근거가 있는지 아닌지 알게 뭐냐는… 시간 없는데 할 말이 많은 사람처럼 문장도 좀 산만한 것 같고. 잔소리 많은 아는 형님이 조금 취했다고 생각하자.
40년째 다운증후군 환자를 위한 학교에 다니는 친구들은 학교가 지루하기만 하다. 어느새 50대에 가까워진 그들은 이제 독립한 성인으로 존중받을 자유를 원한다. 집을 사려 돈을 모으고, 사랑하는 연인과 미래를 약속하며, 직업을 찾기도 하지만, 가족들은 여전히 그들을 성인으로 인정해주지 않는다.
40대 다운증후군 환자들의 아기자기한 귀여운 일상을 보여주다가 독립을 하려고 노력하는 모습을 보여주고 주위 사람들의 반대를 접하는 지점까지는 예상 가능했지만,
영화 끝에서 보여주는 현실의 잔임함에는 혀를 내두르게 됐다. 내가 예민하게 바라본 것일 수도 있지만.
학교 내에서는 계속 독립할 수 있다고 희망을 주는데, 학교 밖에서 실제로 어떤 환경에 부딛히게 될 지 알려주지 않는다.
가족이 비싼 등록금을 대주지 않으면 냉정하게 떠나야 하는 학원같은 곳이었다.
학교에선 결혼을 할 수 있다고 용기를 주면서 반지는 반드시 다이아로 받으라고 타협하지 말라고 조언해주지만,
이 다큐의 아이같은 사람들이나 미 투의 그 똑똑한 사람이나 보편적인 삶을 누리기는 녹록치 않다.
임신을 하게 되면 기형아/다운증후군 검사를 하게 되는데, 그 때의 불쾌함이 떠올랐다.
(이에 대한 친절한 설명이 없었으므로) 그 땐 ‘아니 그럼 기형아라고 판명나면 죽이기라도 할꺼야?’라는 반발심이 있었는데, 이런 검사는 더 나은 결과를 만들기 위해 필요하다는 의견도 있다.
무력한 다운증후군 환자에 대한 다큐를 보며 먹먹했던 마음은 결국 어쨌든 딸램이 아무 불편함 없이 세상에 나와서 다행일 뿐이라는 간사한 감사함으로 수렴되고 말았다.
그들도 가족도 쉽지 않다.
라스트맨 인 알레포 (Last Men in Aleppo)
5년간 지속된 내전. 약 삼십오만 명만 남은 알레포 주민들은 언제 닥칠지 모르는 폭격에 대한 불안감 속에 살고 있다. 자원활동가로 이루어진 민간 구조대 ‘화이트 헬멧’은 붕괴 직전의 알레포 현장에서 싸우고 있다. 작은 생명들조차 폭격으로 사라져 가는 일상 속에서, 그들은 인류에 대한 회의와 더불어 자신의 선택에 대한 의문과도 싸우고 있다.
시리아 내전에 관한 이야기. 정말 이렇게 사람이 죽어나가는 게 말도 안된다는 생각이 끊이지 않는다.
영화 초반부 무너진 건물 잔해 사이에서 아이들을 구해내는 장면이 시각적으로 꽤나 인상적인데,
(죽은 아이 산 아이 반반이지만) 모두 출산 장면을 떠올리게 한다.
러시아 저 놈들은 또 왜 와서 민간인을 학살하는가 싶어서 도저히 상식적으로 이해가 안되서 영화를 보는 중간중간 시리아 내전에 대해 검색도 해봤다.
그러나 워낙 복잡한 양상이라 곧 이해하기를 포기.
그렇게 미친 듯이 활약하는 민간 구조대 주인공들은 결국 모두 사망한다.
아마 영화에 등장한 대부분이 사망했을 것 같다.
이 동네도 당장 답이 없다.
데이빗 보위: 지기 스타더스트 마지막 날들 (David Bowie: The Last Five Years)
예측 불가능한 아티스트 데이빗 보위. 그의 작업은 늘 흥미로웠고 도전적이었으며 대중의 예상을 뛰어넘었다. 현대 대중음악 역사상 가장 위대한 아티스트 중 한 사람이었던 데이빗 보위의 마지막 5년을 다룬 이 다큐멘터리는, 관객들이 그를 만들어낸 ‘크리에이티브’ 전략을 엿볼 수 있게 한다.
처음부터 본 건 아니지만.
보는 내내 입 벌리고 대단하다고 밖에 생각할 수 밖에.
모 세미나에서 전길남 박사가 나와서 이야기 할 때의 그런 느낌과 비슷했는데,
그 나이에도 불구하고 전혀 사고가 막혀있지 않았구나 생각도 들고.
그렇다고 데이빗 보위의 음악을 즐기게 된 건 아니지만.
리처드 링클레이터: 꿈의 연대기 (Richard Linklater - Dream is Destiny)
할리우드 거대 자본의 영향권 밖인 텍사스 오스틴에서 등장하여, 독립영화 제작 방식을 치열하게 실천하려 분투한 어느 감독을 바라보는 독특한 시선. 희귀한 영상 자료와 언론, 링클레이터 본인과의 인터뷰, 영화 제작 메이킹 필름 등을 볼 수 있고, 매튜 맥커너히, 패트리샤 아퀘트, 에단 호크, 잭 블랙, 줄리 델피, 케빈 스미스 등 함께 작업한 배우들도 만날 수 있다.
이게 다 이 양반 영화였어?라는 놀라움의 연속이었다.
데이빗 보위처럼 타협 (거의) 없이 새롭게 도전하는 모습에서 둘이 좀 비슷한 느낌도 있었다.
영화를 익히는 초반에 기초를 충실히 닦는 모습도 인상적이었고,
역시 체력이 되는 애들은 집중력이 좋구나 싶기도(운동을 더 이상 못하게 되자 도서관에 짱 박힘).
스쿨 오브 락에서는 나름 상업 영화의 틀 안에 있었지만, 그 캐릭터에 자기 모습을 많이 녹여낸 것도 재미있었다.
씨앗: 우리가 몰랐던 이야기 (SEED: The Untold Story)
인류가 탄생한 직후부터 씨앗은 소중하게 다뤄야 할 가장 중요한 것이었다. 지난 세기 동안 우리가 가지고 있던 종자 품종의 94%가 사라졌다고 한다. 생명공학 기업이 종자와 농부, 과학자, 변호사들 그리고 토종 씨앗의 수호자들까지도 지배하게 되면서, 우리 식량의 미래를 지키기 위한 다윗과 골리앗의 싸움은 시작되었다.
대충 대충 구경했지만, 그 다양한 씨앗의 아름다움이 꽤나 인상깊었다.
씨앗을 통해서 우리가 얼마나 경제의 논리로 다양성을 멸종 시키는가를 다루는 처음 부분은 재미있었다.
음소문자(音素文字, alphabet)는 하나하나의 문자가 원칙적으로 하나의 자음 또는 모음의 음소(音素)를 나타내는 문자 체계이다. 자음과 모음에 대응하는 각각의 문자가 따로 존재하는게 다른 종류의 문자와의 다른 점이다. 로마 문자, 한글, 키릴 문자, 그리스 문자 같은 것들이 음소 문자 중 하나다.
위키디피아 설명에는 sets of letters used in written languages라는 설명으로 시작해서,
"alphabet" is a script that represents both vowels and consonants as letters equally라는 표현도 나온다.
자음과 모음을 동일하게 하나의 글자로써 표현하는 것인가 본데…
라라벨 매뉴얼에서 alphabet을 ‘알파벳[자음과 모음]’이라고 표현하신 건 이제 이해가 됐다.







 - 그가 만들었으니 그가 옳다!
- 그가 만들었으니 그가 옳다!