식은땀이 흐르는 Redis 서버 교체기 2편
목차
- 낡은 캐시 서버를 교체하라
- 섣부른 서버 교체, 죄송합니다
- ElastiCache의 지표들을 이해해봅니다
- 애플리케이션 서버에서 문제를 찾아봅시다
- 살려야 한다
- 살려는 드렸는데…
- 마무리
- 부록 : 도입하는 과정에서 알게 된 잡다한 지식
“식은땀이 흐르는 Redis 서버 교체기 1편”에서 이어지는 글입니다.
이전 글에서는 섣부르게 Redis 서버를 교체하면서 장애를 맞았던 경험을 공유하고, 놓치고 있던 지표를 정확히 이해하기 위해 찾아본 문서를 소개했습니다.
각종 지표를 통해 신규 커넥션의 수 혹은 많은 커넥션 자체가 Redis 서버의 CPU 사용량을 늘리고, 이것이 장애로까지 이어졌을 거라고 분석했습니다.
이번 글에서는 Redis 서버에 부하를 줄이기 위한 여러 가지 시도와 앞으로 더 시도해볼 만한 방법을 공유합니다.
애플리케이션 서버에서 문제를 찾아봅시다
persistent connection
1차 시도 때 기존 사용하던 서버가 교체된 후 애플리케이션에서의 요청이 사라졌음에도, 현재 연결(CurrConnections) 지표는 줄어들지 않고 그대로 유지되는 것이 마음에 걸렸습니다.
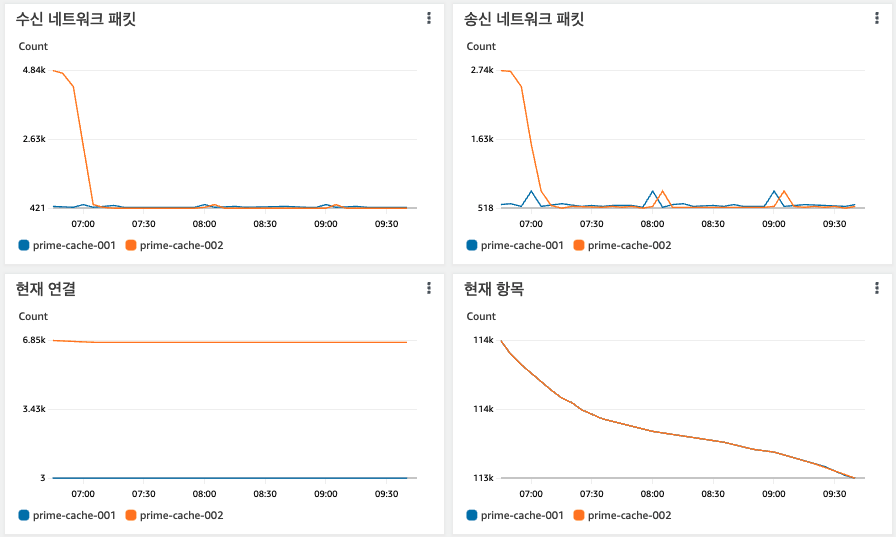
- 애플리케이션 서버로부터 연결이 들어오지 않아 수신/송신 네트워크가 줄어들고 캐시 된 아이템(현재 항목)은 하나씩 만료돼가는 모습
- 좌 하단의 현재 연결 지표는 거의 줄어들지 않았습니다
찾아보니 비슷한 경험 stackoverflow에도 올라와 있었습니다.
여기서 언급된 Redis 문서에서 Client Timeouts 부분을 보시면 Redis에서는 원래 연결을 끊지 않는 것으로 보입니다.
By default recent versions of Redis don’t close the connection with the client if the client is idle for many seconds: the connection will remain open forever.
그동안 커넥션 수가 늘어남에 따라 문제가 발생하지 않았을까 강한 의심을 하고 있었기 때문에 커넥션을 줄일 방법을 좀 더 찾아보기로 했습니다.
위 Redis 문서에 나온 것처럼 timeout 설정도 그 방안 중 하나인데, Amazon ElastiCache for Redis는 CLI로 수정이 되지 않고 파라미터 그룹을 생성해서 적용해야 합니다.
동료 중 한 분은 persistent 옵션을 사용해보는 건 어떨지 제안을 주셨는데
파라미터로 쉽게 적용 가능하고, 여러 서버군 중에 일부만 환경변수로 쉽게 제어도 할 수 있었으므로 timeout 설정보다 먼저 시도해보기로 했습니다.
Redis 설정에 'persistent' => 1, 한 줄만 추가하면 됩니다.
'redis' => [ |
한번의 request 안에서의 연결은 재사용되는지 궁금했습니다.
// 코드는 중요하지 않음. 한번의 put과 여러번의 get을 호출하는 상황 |
연속으로 5회 request 시도해봤을 때는 신규 connection이 하나만 생성되는 걸 확인했고, 아래와 같이 동시에 여러 번 쏴본 테스트에서도 개선 효과가 뚜렷했습니다.
ab -n 50 -c 10 https://test_url |
- PERSISTENT=1 -> 신규 커넥션 15
- PERSISTENT=0 -> 신규 커넥션 50
5일에 걸쳐 영향 범위가 적은 서버부터 차례로 적용해보았습니다. 아래는 마지막 트래픽이 많은 서버군에 적용된 후의 모습인데, Current/New connection 지표는 예상대로 바뀌었습니다.
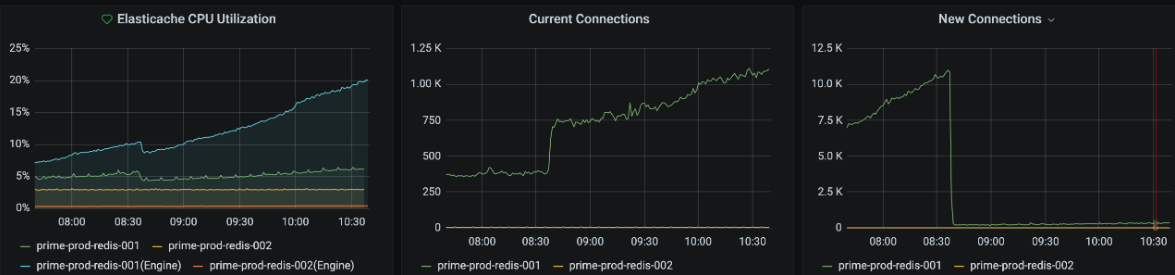
- 신규 커넥션이 줄었기 때문에 CPUUtilization이 낮아진 건 예상했지만 EngineCPUutilization 수치도 상당 부분 내려간 것이 의외였습니다.
- 여기에는 보이지 않지만, 애플리케이션 서버 자체의 CPU 지표에는 큰 변화가 없었습니다. 다만 애플리케이션 서버 쪽 ELB Latency는 소폭(약 10ms) 낮아진 것도 확인할 수 있었습니다.
애플리케이션 서버 스펙을 올리기
커넥션을 물고 있는 애플리케이션이 조금 더 빠르게 처리되고 끝날 수 있게 애플리케이션 서버의 스펙을 두 배로 올리는 실험도 해보았습니다.
Pod의 CPU request를 두 배로 늘려주니 Pod 수는 절반 이하로 줄었고, Current connections가 약 10%가량 줄어들었습니다.
New connection에서는 체감할 만한 변화는 없었습니다.
애플리케이션에서 문제 찾기
코드에서는 잘못된 사용 패턴이 없는지도 점검했습니다.
7년 이상 된 서비스라, 과거엔 성능에 거의 영향을 주지 않던 코드가 시스템에 큰 충격을 주는 경우를 종종 만나게 됩니다.
has-get / has-del 패턴 없애기
New Relic에서 확인했을 때 Redis를 활용하는 사용량 기준 상위권에 속하는 코드에서 불필요하게 한 번 더 쿼리하는 패턴을 발견합니다.
‘캐시가 존재하면 가져온다’, ‘캐시가 존재하면 지운다’와 같은 패턴입니다.
if ($this->cache->has($cacheKey)) { |
Laravel의 cache repository의 구현체를 보니
vendor/laravel/framework/src/Illuminate/Cache/Repository.php:68
public function has($key) |
get을 시도한 후 null 체크만 하면 되는 것이었습니다.
if ($cached = $this->cache->get($cacheKey)) { |
client에서 polling 줄이기
서비스를 시작한 후로 많은 세월이 흘러, 클라이언트에서 polling 하는 API가 하나둘 씩 늘어나게 되었습니다.
매 polling마다 Redis를 활용한 체크 로직이 많았는데, polling 하는 데이터의 성격상 한번에 쿼리해도 되거나 push로 대체할 수 있는 것들이 보였습니다. 해당 API를 담당하시는 분들이 이 부분도 빠르게 개선해주셨습니다.
phpredis
C로 작성된 PHP extension인 PhpRedis는 pure PHP인 Predis 보다 성능 면에서 월등한 것으로 나타납니다.
벤치마크 참고 : https://akalongman.medium.com/phpredis-vs-predis-comparison-on-real-production-data-a819b48cbadb
Laravel 6.x 버전부터는 문서에서 phpredis를 predis보다 먼저 소개합니다.
https://laravel.com/docs/6.x/redis
we encourage you to install and use the PhpRedis PHP extension via PECL
phpredis로 전환하기 위해선 아래 블로그를 참고하시면 됩니다.
https://www.lesstif.com/dbms/php-phpredis-redis-23757275.html
그런데 phpredis가 설치된 이미지를 빌드해서 서버를 띄워봤지만, 연결이 되지 않았습니다.
일단 특수한 상황으로 보이긴 했는데요.
https://bugs.php.net/bug.php?id=79501
2022년에 올라온 PHP 버그 리포트에서도 비슷한 문제를 발견했는데, PHP 7.4 버전에서 TLS 1.3을 사용할 때 유독 문제가 발생한다는 것이었습니다.
https://github.com/phpredis/phpredis/issues/1881
phpredis에 관한 이야기지만 PHP와 Linux 둘 중 하나에 버그가 있는 게 아니냐는 논의이고,
마지막에 보면 커넥션을 수없이 열고 닫는 과정에서 발생하는 것 같고 레디스 사용을 줄이면서 오류도 줄였다는 내용도 보입니다.
PHP 8.0 버전에서는 문제없는지 정도만 빠르게 확인해봤습니다.
PHP 8.0 + 라라벨 기본 애플리케이션으로 서비스를 올리고 테스트해 보니 잘 연결이 되는 걸 확인했습니다.
어쩌면 PHP 7.4 + TLS + 아이디/비번으로 연결하는 경우만 그럴 수도 있어서 더 찾아보면 방법이 있을 수도 있는데, 그 노력을 아껴서 다른 곳에 쓰기로 했습니다. 곧 PHP 8버전대로 올릴 때 자연스레 PhpRedis로 이전할 수 있을 것 같았습니다.
(버전업이란 게 항상 그렇듯 아직 진행은 안 되고 있는데 말이죠..)
살려야 한다
이미 간이 콩알만 해진 관계로 한 번에 여러 가지를 시도하지 않고, 단계별로 진행해 볼 계획을 세웠습니다.
- 6.2 버전의 신규 Redis 서버를 RBAC 인증도 가능하고 현재처럼 특별히 인증 없이 default user로 접근할 수도 있게 설정
- default 유저를 사용해 서비스에 투입
- 이때 cache.m5.4xlarge(16vCPU)로 좀 더 과감하게 스케일업
- 이후 RBAC 적용하고
- 이후 default 인증 제거
배포 전 미리 두 가지 인증 방식으로 연결이 잘 되는지 확인해봤습니다.
TLS 연결 설정은 나중에 변경하기 어려운 상황이어서 default 유저에 TLS 연결로 우선 적용해보기로 했습니다.
상용 환경 투입
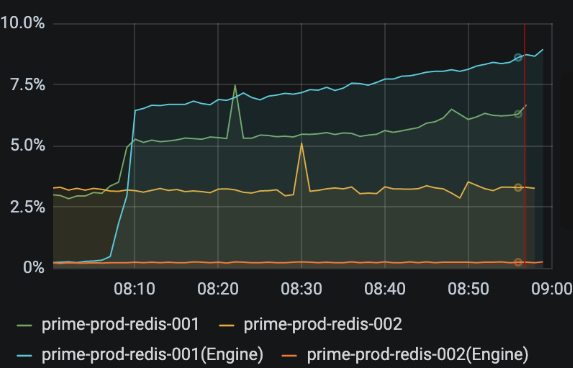
- TLS 연결 + Redis 인스턴스 타입 교체 + default 인증
- cache.m5.xlarge(4vCPU) -> cache.m5.4xlarge(16vCPU)
- 예상대로 EngineCPUutilization 지표(파란색)가 높아졌고, 16코어의 큰 인스턴스를 쓰기 때문에 CPUUtilization 지표는 참고만 하고 예민하게 보지 않기로 했습니다.
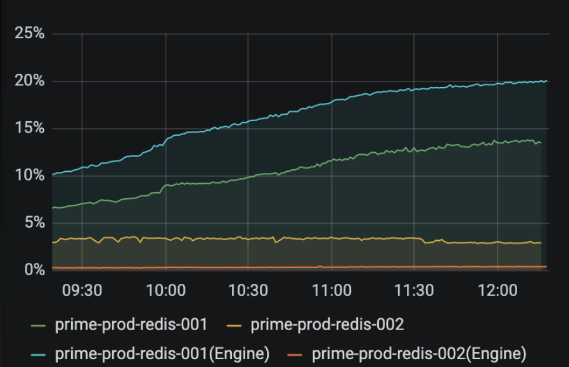
RBAC은 조심스럽게 적용했는데, 여러 서버군을 사용량과 적고 영향 범위를 기준으로 5가지로 나누고, 서비스에 영향이 적은 서버들부터 5일에 걸쳐 적용했습니다. 아래는 마지막으로 적용한 이후의 그래프인데, AUTH 커맨드의 추가 실행이 필요하므로 예상대로 EngineCPUutilization가 올라갔지만, 서버는 안정적으로 유지되고 있습니다.
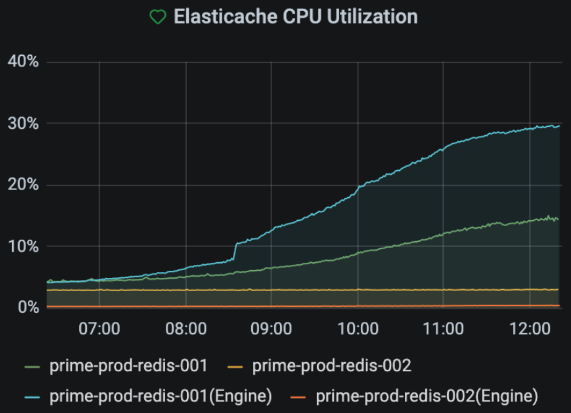
그리고 일주일 후, default 인증을 제거하면서 최종 마무리가 됐습니다.
살려는 드렸는데…
마지막에 꽤 큰 인스턴스 타입으로 바꾸었기 때문에, 이제 비용을 줄이기 위해선 더 낮은 사양으로 낮춰보거나 현재 사양이 적정하다는 것을 확인해야 하는데, 추가 개선안으로 적용해볼 것이 아직 많이 남아 고민 중에 있습니다.
read connection
replica를 더 두고 reader endpoint를 사용해서 읽기 연결을 분산하는 방법입니다. 현재의 replica는 장애 대비로만 존재하기 때문에 읽기 전용 연결을 하려면 replica를 추가해야 할 것입니다.
그런데 Reader endpoint를 바라보는 커넥션을 별도로 두고, 읽기만 발생하는 곳에서 명시적으로 읽기 커넥션을 지정해야 하는데, 사용성이 좋지 않고 검토하고 수정할 범위가 넓어서 당시엔 배제하였습니다.
캐시 서버를 분리
전체 애플리케이션이 레디스 클러스터 하나에 붙어 운영하다 보니 그만큼 레디스 서버 스펙도 높아질 수밖에 없는 구조입니다.
하위 서비스별로 각자 사용할 캐시를 분리하면 위험을 분산하고 성능을 높일 수 있습니다. 혹은 세션 등 공통으로 사용할 만한 부분부터 분리해나가는 것도 고려해볼 만합니다.
경계 확인하기
현재의 Redis 스펙으로 얼마나 버틸 수 있는지 확인해봐야 합니다.
현재는 EngineCPUutilization 지표가 피크 기준 30% 선을 유지하지만, 몇 % 정도 더 오르면 다시 교체하거나 최적화를 고민해야 할지 정해놔야 합니다.
Istio
제가 커넥션 문제로 고민하고 있을 때, 10년 전 같이 일했던 선배 개발자들과 이야기를 나눴었습니다. Redis는 아니었지만 캐시를 많이 사용하던 서비스였고, 그때도 커넥션 관리에 문제가 많아서 커넥션 풀을 제공하는 중간 서버를 하나 두었었다는 이야기를 들었습니다.
직접 만드는 것도 방법이겠지만, Envoy Proxy라는 솔루션을 활용할 수도 있습니다. Istio가 제공하는 수많은 기능 중에서도 proxy나 서킷 브레이커가 특히 유용할 것으로 보이는데, 애플리케이션을 수정하지 않고도 쉽게 붙일 수 있다는 점에서 긍정적으로 도입을 검토해볼 만합니다.
reddit에서의 답변
https://www.reddit.com/r/PHP/comments/sikoux/are_persistent_connections_to_mysqlredis_good/
- envoy proxy를 sidecar로 붙여서 활용하는 방법 : “앱은 추상 유닉스 소켓을 사용하여 envoy에 연결하고 envoy 자체는 연결을 지속적으로 다시 만들 필요가 없도록 일정 시간 동안 연결을 유지합니다.”
Envoy를 사용하여 PHP Redis 클라이언트 성능을 개선하는 방법
https://angelbear.github.io/blogs/2021/07/envoyfilter-improve-php-redis-client/
- 주의할 점으로
- 중간자가 존재하므로 개별 읽기/쓰기 성능은 낮아짐 -> 전체 성능은 올라감
- 너무 많은 ESTABLISHED 연결 -> 너무 많으면 새로운 연결에 문제가 생길 수 있음
- timeout 설정으로 커넥션이 너무 오래 지속되지 않도록 처리 필요
cachewerk/relay
https://github.com/cachewerk/relay
아직 안정화는 안 됐지만, 검색 결과를 in-memory cache에 저장해서 캐시 요청을 줄이는데 활용할 수 있음.
더 읽어보기
Best practices: Redis clients and Amazon ElastiCache for Redis
- 복제본에서 읽기 / 쓰기 분산
- Lettuce, Python에서의 연결 pool 구성
- 클러스터 모드일 때 해볼 만한 팁
등이 포함되어 있습니다
마무리
오래전 글이지만, 이 작업 이후 다시 읽고 새롭게 다가왔던 문장을 소개하며 마칩니다.
Richard Cook의 How Complex System Fail 사례
- 모든 실무자의 행동은 도박이다.
장애 이후에 실패는 종종 피할 수 없는 것처럼 보이며, 실무자의 행동은 실수로 보인다. 그러나 모든 실무자의 행동은 실제로 도박, 즉 불확실한 결과에 직면하여 발생하는 행동이다. 불활실성의 정도는 변할 수 있다. 실무자의 행동이 도박이라는 사실은 장애 이후에 알게된다. 일반적으로 사후 분석에서는 이러한 도박을 빈약한 도박으로 간주한다. 그러나 성공적인 결과 또한 도박의 결과이기도 하다.
1차, 2차 그리고 안정적으로 유지하게 된 최종 적용 과정에서도 많은 도박 요소가 있었습니다.
그것이 도박이었다는 것을 뼈저리게 느끼게 해 준 시간이었고, 오랜 시간 쌓인 기술 부채를 도박으로 탕감하려는 시도를 했구나 싶었습니다.
마지막 시도 과정에서는 심지어 이런 일도 있었습니다.
Pod의 CPU request를 두 배로 늘려주는 과정에서 CPU 기준의 AutoScaling이 동작했는데, 그때가 8시 반쯤 트래픽이 적을 때여서 minimum pod 수만 남기고 모두 삭제되었습니다.
9시 정각, 모 업체에서 오픈런 이벤트로 많은 요청을 보내기 시작했습니다. 웹서버의 절대적 수가 부족한 상황에서 갑자기 커다란 트래픽을 맞아 휘청했죠. ‘좋은 하드웨어로 갈아주는데 설마 무슨 문제가 있겠어?’라고 안일하게 생각했다가 다시 한방 크게 먹었습니다.
하지만 이 날 무사히 넘어갔어도 언젠가 누군가 (누구의 탓인지 모른 채) 같은 문제는 겪었을 것입니다.
위에 소개드린 “How Complex System Fail”을 요약한 GeekNews의 글만 읽어보고는 잘 알지도 못하면서 너무 쉽게 선택한 스스로를 반성했습니다. 그건 그것대로 반성할 만 하지만,
원문을 읽어보니 도박이라서 안 좋다는 걸 강조하는 것보다는, 복잡한 시스템에서의 선택은 불확실성을 내포하는 도박과 같다는 의미로 읽혔습니다.
장애의 원인과 해결책을 너무 쉽게 판단하는 것 역시 경계해야 할 일이라고.
(사실 원문이나 링크된 강의 동영상에서의 문장이 너무 어려워서 잘 이해했는지 모르겠어요)
내가 맡은 서비스가 복잡한 시스템은 맞는 건가 의문도 들지만, 많은 노하우를 쌓을 수 있었던 경험이었습니다.
위 Richard Cook의 글의 마지막 항목을 읽어볼까요?
- 실패없는 작업에는 실패 경험이 필요하다.
… 중략 … 오류와 긴밀한 접촉이 필요합니다. 운영자가 시스템의 한계를 식별할 수 있는 시스템에서 보다 강력한 시스템 성능이 발생할 수 있습니다.
마지막 시도에서 cache.m5.xlarge에서 cache.m5.4xlarge로 과감하게 올렸지만, cache.m5.2xlarge로는 버틸 수 없었을까 미련이 남기도 합니다. AUTH 커맨드가 추가되고 TLS 연결을 위한 추가로 필요한 성능이 넉넉잡아 각각 2배로 필요하다고 가정하면, 최초 cache.m5.large에서 4배로 성능을 높인 cache.m5.2xlarge로도 운용 가능하지 않을까 생각도 듭니다.
현재는 피크에 30%까지만 올라가고 있어서 여유는 있습니다. 당장 무리하게 내릴 생각은 없는데, 문제가 생기기 시작하는 경계를 확인하지 못해서 그만큼의 불안함을 비용으로 지불하고 있구나 생각이 들었습니다.
부록 : 도입하는 과정에서 알게 된 잡다한 지식
SLOWLOG
Redis에는 SLOWLOG 커맨드가 있습니다.
오랜 시간 수행되는 쿼리는 없는지 확인 해볼 수 있습니다. 이번 커넥션 오류와 관련해서도 체크해보았지만, 특별히 느린 커맨드가 보이진 않았습니다.
SLOWLOG 확인 예시:
레디스호스트:6379> SLOWLOG LEN |
Laravel JWT Token Blacklist
서비스에 일시 들어갔다 나온 서버에 무작정 접근해서 문제가 될 만한 데이터가 있는지도 확인해봤습니다.

위 캡쳐와 같이 laravel:로 시작하고 valid_until 정도의 값만 갖고 있는 데이터가 다수 있는 걸 확인했습니다. JWT-auth에서 사용되는 것 같다는 동료의 조언에 따라 뭔가 짚이는 게 있어 실험을 해봤습니다.

이 캡쳐는 로컬 레디스에서 데이터를 깨끗하게 지운 후, 클라이언트에서 로그인/로그아웃을 세 번 정도 한 결과인데요.
로그아웃을 할 때마다 해당 토큰을 blacklist에 영원히(ttl:-1) 저장합니다.
laravel:629ef98ae36a3133817307:standard_ref 이런 식의 키인데, 값은 만료된 키를 저장하고 있죠.
[ |
현재는 이런 데이터가 영원히 늘어나기만 하는 구조입니다.
- 관련 코드는 \Tymon\JWTAuth\Manager::invalidate() 참조
비활성화된 토큰으로 인증을 통과하지 못하게 막는 건 중요합니다. 그러나 발행된 모든 토큰을 영원히 저장하는 것도 효율적이지 않으므로 한번 모두 삭제하기로 했습니다. 캐시라면 언제든 초기화될 수 있는 데이터라고 생각하고 운용하는 것이 좋다고 생각하기도 하고요. 누군가 마침 만료된 토큰을 구해서 접근할 경우 보안에 구멍이 생기기도 하겠죠. 완벽한 방법은 아니지만, 저희 애플리케이션에서는 강제 만료 시간을 설정할 수 있게 해 놓고, 이보다 이전에 발행된 토큰은 사용할 수 없게 보완하였습니다.
Redis 6.0 default user 버그
옆 팀에선 Redis 6.0 버전 때문에 개발 환경에서 장애가 발생한 적이 있었습니다.
default user를 사용하지 못하게 권한을 조정하는 작업 중이었는데, Redis 6.0 버전에선 default user에 권한이 없을 때 HELLO 커맨드가 실패하는 버그가 있었습니다.
이는 6.2.2 버전부터 해결 됐습니다.
< 끝 >