테스트를 돌리기 전 특별히 bootstrap할 게 없으므로 vendor/autoload.php를 bootstrap에 명시했고,
testsuite 명은 나중에 바뀌겠지만 일단 대충 넣고,
tests라는 디렉토리에 있는 Test.php로 끝나는 파일(예: parseTest.php)을 모두 검사하도록 했다.
PHPUnit with PHPStorm
다른 에디터를 쓰는 분들은 다른 각자 알아서 찾아보면 될 것이고, 여기서는 간단히 PHPStorm에서 설정하는 법만 적어본다.
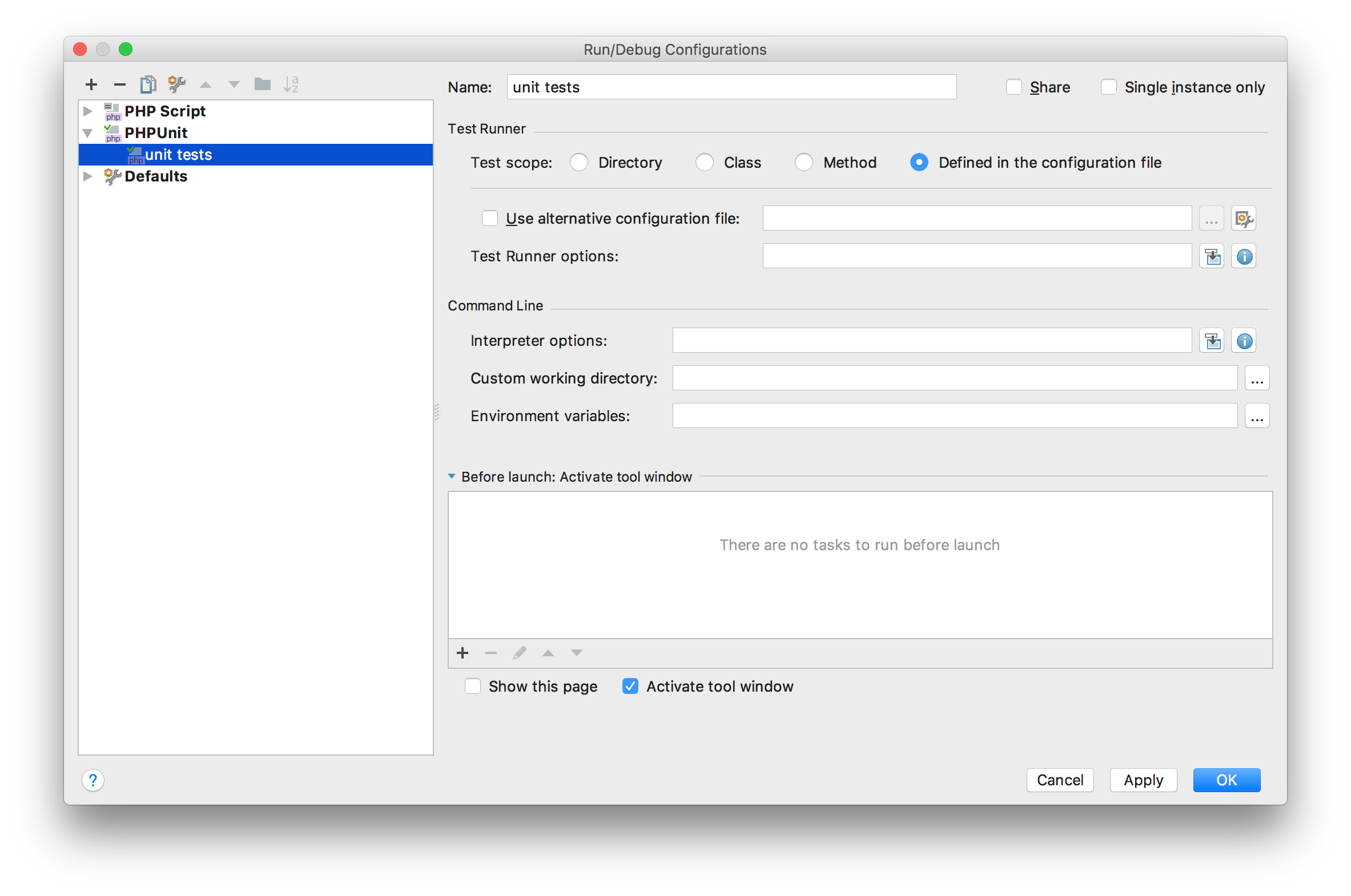
Run | Edit Configurations 메뉴에서 + 버튼을 눌러 PHPUnit 선택.
Test Runner > Test Scope을 `Definded in the configuration file’을 선택한다.
바로 아랫줄 제일 오른쪽에 보이는 설정 버튼을 누르면 Test Frameworks 설정 창이 나온다. (만약 처음 설정/실행한다면 창 아래쪽에서 configuration file에 문제가 있으니 수정하라고 Fix 버튼이 보일 수도 있다. 이걸 눌러도 같은 창이 나온다.)
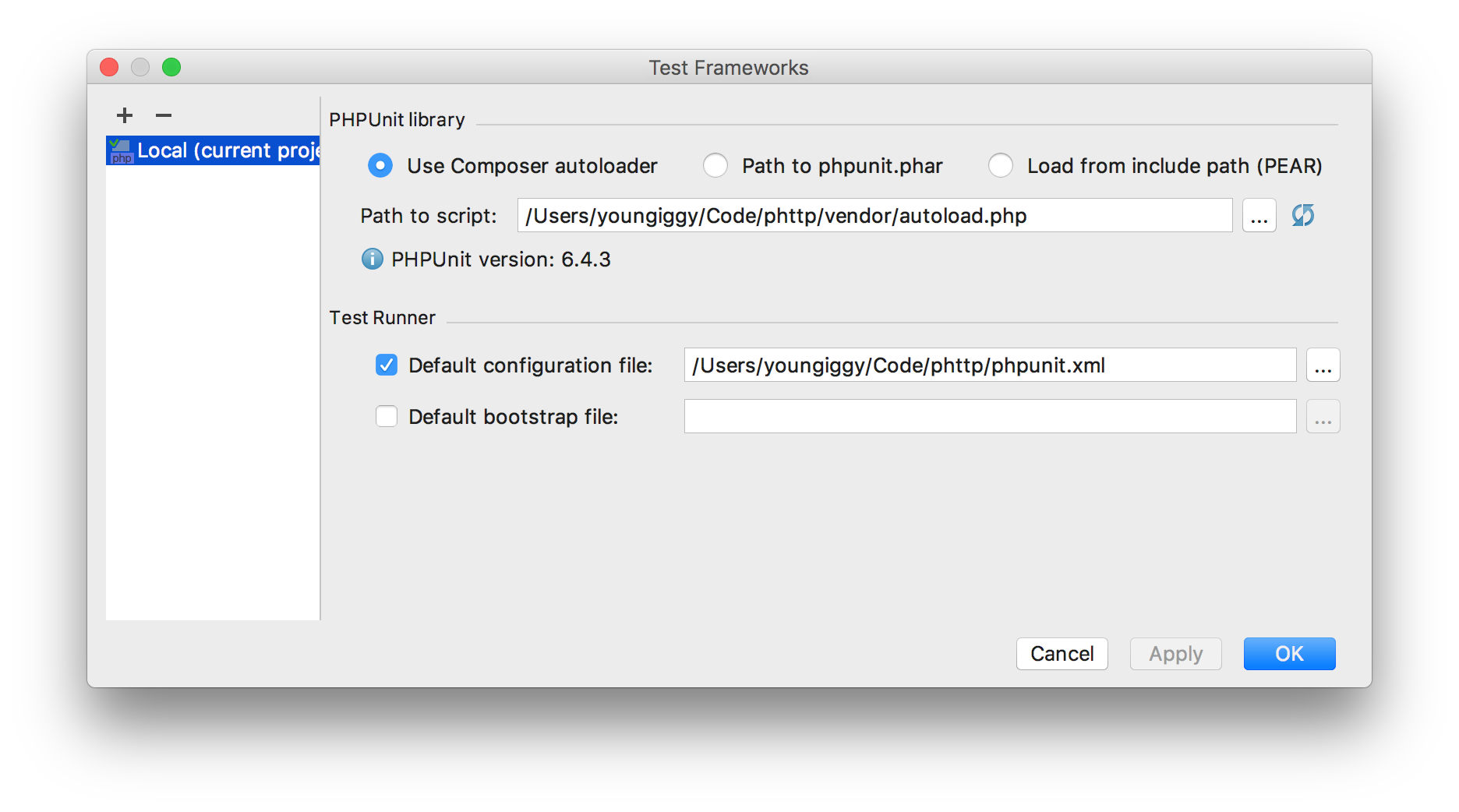
+ 버튼을 눌러 Configuration type을 PHPUnit Local로 추가한 후,
PHPUnit library > Use Composer autoloader 선택하고 Path to script는 … 버튼을 눌러 자신의 vendor/autoload.php을 선택하면 된다.
그 아래 Test Runner 옵션에서는 Default configuration file을 체크하고 앞서 만든 phpunit.xml을 선택한다.
그리고 실행!
테스트를 작성하지 않았으므로 No tests executed! 같은 메시지가 보이면 정상이다.
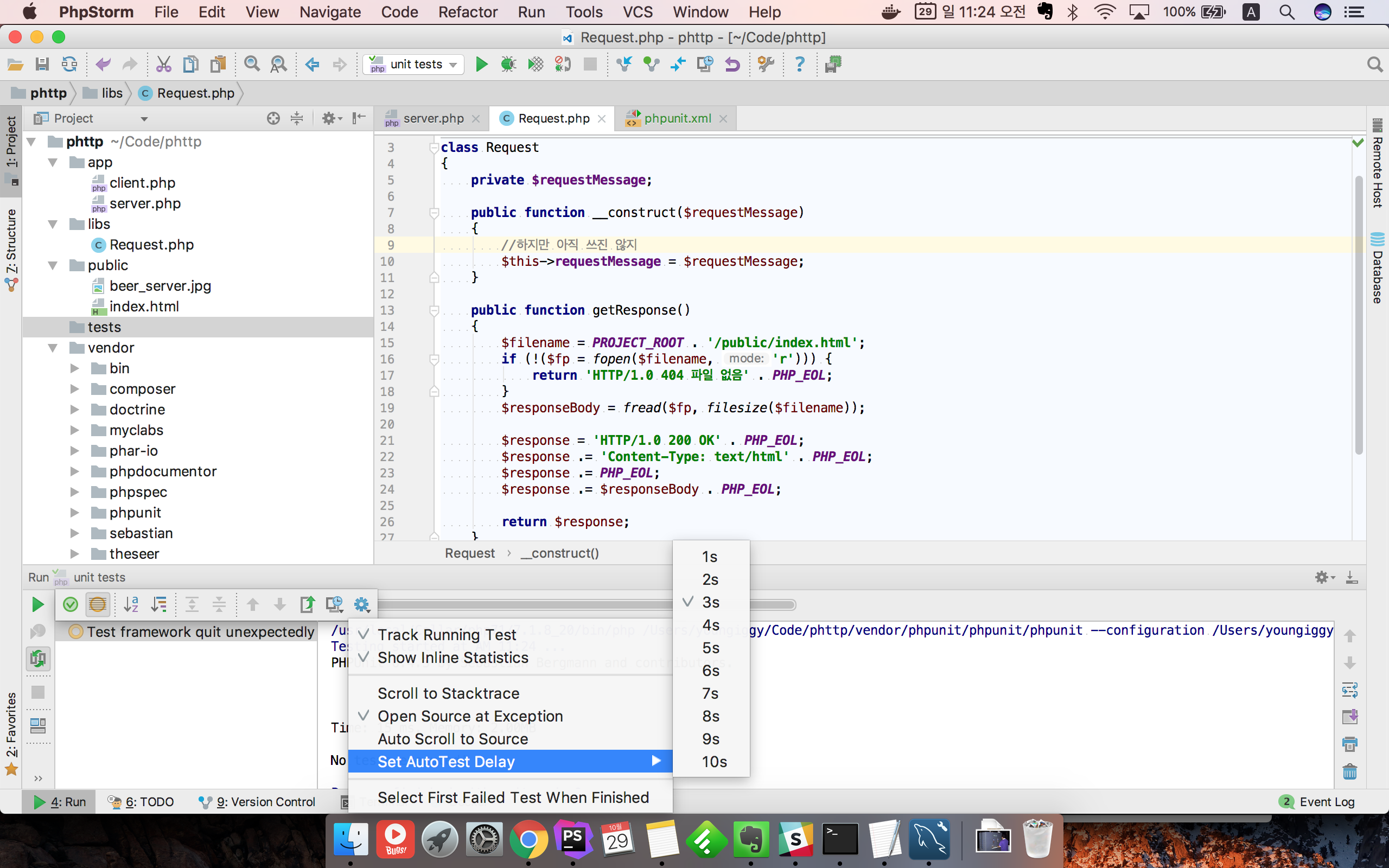
실행창에서 Toggle auto-test를 눌러 놓으면 뭔가 수정이 될 때마다 테스트가 실행된다.
하지만 개발하다보면, 주석을 넣는다거나 공백을 삽입하는데도 test가 실행되므로 종종 눈엣가시가 된다.
이럴 때는 AutoTest Delay값을 늘려주면 좀 낫다.
나중에 테스트가 엄청 많아지면 현재 개발하는 모듈 이외의 클래스도 단위테스트가 돌게 될텐데, 이 때는 phpunit.xml에서 테스트 단위를 나누면 된다. 하지만 예상컨대 이 프로젝트에선 그렇게까지 테스트가 많아질 것 같지 않다.
결론
이제부터는 뭔가 추가/수정할 때마다 미리 테스트를 만들고 실패하는 것을 확인하고 이를 만족하는 기능을 개발하게 될 것이다.
현재 추가/수정하는 코드가 시스템을 망가뜨리지 않는다는 최소한의 보장을 받을 수 있다.
하지만 서버 코드의 많은 부분이 file이나 directory를 읽어야 하는데, 이런 부분은 unit test 만으로 해결 안될 수 있다.
(만약 서버에서 적절한 시작줄을 안 보내주면 Postman은 Could not get any response라며 응답이 오지 않은 것으로 간주한다.)
Postman에서 받은 응답 메시지 본문은 아래와 같다.
you sent : GET / HTTP/1.1 Host: 127.0.0.1:1337 Connection: keep-alive Cache-Control: no-cache User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36 Postman-Token: df3ef030-2b6f-76c3-30d9-304ebb426a41 Accept: */* Accept-Encoding: gzip, deflate, br Accept-Language: ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4
서버에서 응답 본문 앞에 붙여둔 you sent : 한 주를 제외하면 나머지는 HTTP 클라이언트(여기서는 Postman)가 요청 시 붙여 보낸 것이다.
크롬에서 보내면?
you sent : GET / HTTP/1.1 Host: 127.0.0.1:1337 Connection: keep-alive User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36 Upgrade-Insecure-Requests: 1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate, br Accept-Language: ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4
다시 서버 소스를 돌아보자.
지금은 무조건 HTTP/1.0 200 OK라고 응답하게 되어있다.
클라이언트는 HTTP/1.1을 지원하기 때문에 이 프로토콜 버전을 기준으로 헤더를 붙여 요청했지만
우리 서버는 ‘난 HTTP/1.0까지만 지원하는 서버라서 1.0 기준의 헤더를 보낼 거야’라는 의미로 응답에 HTTP/1.0 200 OK를 리턴한다.
브라우저에서 index.html 확인하기
저기 저 아주 간단한 서버 소스에선 메시지 본문을 클라이언트가 보낸 데이터를 그대로 돌려줬는데,
시행착오를 최대한 줄이기 위해 앞에서 소개했던 HTTPServer부터 분석을 해보기로 했다.
composer.json에 있는 php-cgi binary에 대한 의존성 때문인데(HTTPServer requires the php-cgi binary), 이 놈을 왜 넣었을까 궁금했다.
이 서버는 4개의 파일로 구성됐다.
cgistream.php
httprequest.php
httpresponse.php
httpserver.php
http가 prefix로 붙은 파일은 뭐하는 놈인지 이름만 봐도 알 것 같다. cgistream.php을 열어봤다.
오래전에 만든 클래스라서 좀 옛스러운 맛이 있다.
CGIStream class 주석
주석부터 살펴볼까?
/* * CGIStream is a PHP stream wrapper (http://www.php.net/manual/en/class.streamwrapper.php) * that wraps the stdout pipe from a CGI process. It buffers the output until the CGI process is * complete, and then rewrites some HTTP headers (Content-Length, Status, Server) and sets the HTTP status code * before returning the output stream from fread(). * * This allows the server to be notified via stream_select() when the CGI output is ready, rather than waiting * until the CGI process completes. */
CGIStream is a PHP stream wrapper that wraps the stdout pipe from a CGI process.
CGI process로부터 흘러나오는 stdout stream을 wrapping한다. - 이건 뭐 해석한 것도 아니고 안 한 것도 아니고…
참고로, 앞으로 스트림과 stream을 섞어서 쓸텐데(한글 혹은 영어로), 여기엔 큰 의미를 부여하지 말고 그냥 읽으시면 된다.
Stream wrapper class
php.net에 들어가보면,
Allows you to implement your own protocol handlers and streams for use with all the other filesystem functions (such as fopen(), fread() etc.).
나만의 프로토콜 핸들러와 fopen, fread같은 filesystem 함수를 사용할 수 있는 스트림을 구현할 수 있다고 한다.
이 책에 인쇄된 문자를 거의 다 읽긴 했으나, 내가 이 책을 읽었다고 할 수 있을까 생각이 드는 책이다.
목차
PART 1 애자일 개발
PART 2 애자일 설계
PART 3 급여 관리 사례 연구
PART 4 급여 관리 시스템 패키징
PART 5 기상 관측기 사례 연구
PART 6 ETS 사례 연구
APPENDIX A UML 표기법 I: CGI 예제
APPENDIX B UML 표기법 II: 스태트먹스
APPENDIX C 두 기업에 대한 풍자
APPENDIX D 소스 코드는 곧 설계다
먼 나라 이야기라고 생각이 드는 PART 1에서 작은 고민을 얻어왔다면
PART 2에서는 SOLID 원칙을 제대로 이해하기 위한 색다른 관점이 좋았고(그런데 10여 년 전에 출간된 이 책을 두고 색다르다고 해도 실례가 안 되려나).
PART 3부터 익숙치 않은 C++ 문법과 더 익숙치 않은 UML 문법 때문에 눈이 뻑뻑해지기 시작했는데, 결국 부록의 UML 표기법을 먼저 보고올 수 밖에 없었다. 그런데 이 책을 읽는데 별로 도움 안되는 것 같고, 그냥 간단한 규칙 정도만 찾아보고 책을 한번 더 읽는 것이 좋겠다는 생각이 들었다. 아무래도 밥아저씨의 UML 책을 읽어야겠구나 싶을 정도로 UML로부터 설계를 해나가는 모습이 꽤 매력적으로 느껴졌다(현실은 시궁창일 걸 알면서 말이다).
PART 4는 방금 늪에서 빠져나온 여우마냥 숨 좀 고를 수 있는 챕터였지만, PHP/JavaScript를 쓰는 상황에서 패키징에 대한 글을 읽자니 남일 같아서 마음이 편했다.
PART 5에선 PART 3의 급여 관리 사례와 비슷한 포맷이긴 한데, 일단 급여 관리에서 빠져나와 새 인생을 시작한 기분이었으므로 나름 재미있게 읽었던 것 같다.
PART 6도 완벽하게 이해는 못했지만 다시 읽으면 그럭저럭 이해는 될 것 같긴 하다.
APPENDIX B는 전혀 모르겠고..
APPENDIX C가 꽤 인상적이었다. 두 기업에 대한 풍자라고 하는데, 왼쪽엔 그지같은 기업, 오른쪽엔 이상적인 기업을 나란히 덧대어 놓았다. 그동안 왼쪽같은 문화에서만 살았고(그리고 아마 10월부터 또 겪어야 할텐데..), 오른쪽같은 문화를 꿈꾸지만 경험은 없는 상태. 이 책을 힘겹게 읽으면서 좀 지쳤는데, 이 부록을 읽으며 다시 전의가 불타올랐다(하지만 이제 곧 잘 시간). 조금이라도 시도해 보리라 다짐을 해봤다(현실은 시궁창일 걸 알면서 말이다).
APPENDIX D도 너무 좋았다. 10년 전에 쓴 이 책에 10년 전에 썼다는 글을 소개한 내용인데, 공학에서의 최종 결과물은 문서가 되어야 하고, 소프트웨어 공학에서의 문서라 함은 코드 자체라는 주장이다. 그냥 자기계발서 같은 글인가 싶었는데, 이 양반은 진심이었고 다 읽고 나선 진심 공감이 됐다.
결론
다시 읽어야 한다.
읽기 시작하면서부터 몇 번을 다시 읽어야 할까 생각이 들었던 책이다. 지금 바로 다시 읽어야 이 책을 읽기나 했다고 어디가서 얘기라도 할텐데…
내년에 다시 읽어보기로 했다. 누구 안 주고 책장에 잘 모셔두고 내년 초에 다시 읽어보겠다.
실무에서 좀 더 부딪혀보고, 실습해보고, 다시 보면 이해하는 폭이 더 넓어지리라 생각이 든다(현실은 시궁창일 걸 알면서 말이다).
원몰띵
이런 책을 읽으면서 항상 느끼는 거지만…
테스트가 주도하지 않고도 제대로된 소프트웨어를 만드는 게 가능이나 한가…뭐 그런 생각이 든다.