식은땀이 흐르는 Redis 서버 교체기 1편
올여름 Redis 서버 교체 과정에서 여러 번의 장애를 겪은 후 뼈에 새기는 반성문입니다.
목차
- 낡은 캐시 서버를 교체하라
- 섣부른 서버 교체, 죄송합니다
- ElastiCache의 지표들을 이해해봅니다
- 애플리케이션 서버에서 문제를 찾아봅시다
- 살려야 한다
- 살려는 드렸는데…
- 마무리
- 부록 : 도입하는 과정에서 알게 된 잡다한 지식
낡은 캐시 서버를 교체하라
오랜 시간 큰 문제 없이 사용하던 Redis 서버가 있었습니다.
TLS 연결도 없이 default user를 사용했는데, Laravel 애플리케이션의 database.php 파일 설정은 이렇게 간단했죠.
... |
보안취약점 개선 작업을 준비하던 과정에서 EOL 소식도 들었습니다(Redis 버전의 수명 종료 일정 참고).

개선하는 김에 버전도 Redis 6.2 이상으로 올리고
default user를 사용하는 대신 최신 버전에서 지원하는 역할 기반 액세스 제어(RBAC)를 사용한 사용자 인증,
여기에 TLS 연결까지 적용하기로 했어요.
섣부른 서버 교체, 죄송합니다
이제 조금 더 복잡해진 설정.
'redis' => [ |
테스트 환경과 트래픽이 낮은 다른 서비스에 미리 도입해서 잘 동작하는 것은 확인했습니다.
연결 테스트:
# openssl 설치 |
애플리케이션 테스트 by tinker
Psy Shell v0.9.12 (PHP 7.4.33 — cli) by Justin Hileman |
1차 시도
오전 8시경 트래픽이 비교적 많은 서비스에 넣어봤습니다.
저희 서비스는 식당이 주 고객이라서 매장 오픈 시간부터 트래픽이 몰리는데, 특히 11시부터 2시까지를 오전 피크로 보고 있습니다.
AWS에서 운영 중인 API 서버군의 ELB Latency 지표는 일반적으로 130ms ~ 150ms 사이를 유지하고 있습니다.
여기서 ELB Latency란, “로드 밸런서가 등록된 인스턴스에 요청을 보낸 시간부터 인스턴스가 응답 헤더를 보내기 시작할 때까지 경과된 총시간(초)”을 의미합니다. (elb-cloudwatch-metrics 문서 참고)
그런데 오전 11시를 넘어서며 ELB Latency가 급격히 오르기 시작합니다.
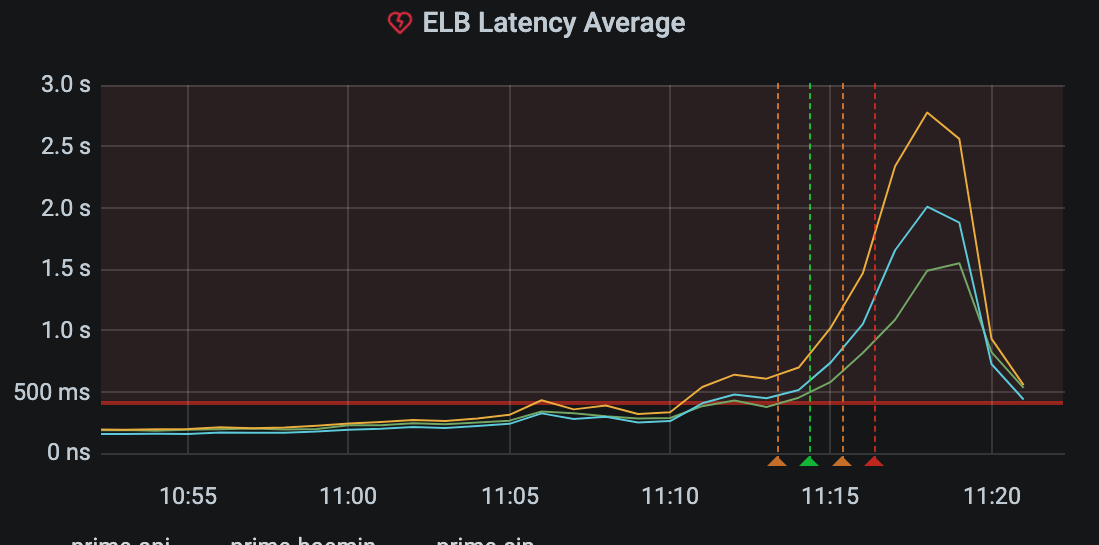
지표를 확인한 순간 바로 롤백을 진행했지만 5분에서 10분 정도의 장애가 발생했습니다.
바로 AWS Premium Support에 case를 열어 어떤 일이 있었는지 문의를 해봤고,
내부 툴로 확인한 결과라며 답변을 주셨는데, 요약하면 이렇습니다.
서비스 투입되고 일정 시간 동안의 지표를 비교해본 결과
- 신 Redis로 교체 시
- CPUUtilization: 15% -> 60% , EngineCPUutiliaztoin: 22% -> 99% , Total Cmds: 기존 대비 거의 두 배로 증가
- HitRate는 투입 후 2시간에 걸쳐 0%에서 51%까지 상승
- 다시 구 Redis로 교체 시
- CPUUtilization: 15% ~ 17% , EngineCPUutiliaztoin: 16% -> 18% , Total Cmds: 20% 증가
추가로 아래와 같이 제안도 주셨습니다.
- 가장 데이터가 적은 시간대에 Redis 교체를 고려
- 기존 Redis의 데이터를 백업 후 Restore 하여 6.2 버젼의 Redis를 시작(캐쉬데이터의 TTL 이 너무 짧지 않으면)
- 기존(cache.m5.large)보다 큰사이즈(cache.m5.xlarge 또는 그 이상)로 시작하였다가, 추후 Online scaling down을 통하여 크기를 줄이는 방법
아마도 RBAC을 적용하면 AUTH 명령을 추가로 실행하기 때문에 전체 커맨드 수가 많이 증가했을 것이고, 캐시가 비어 있는 새로운 서버를 띄우면서 HitRate가 지나치게 낮은 것이 문제가 됐을 거라고 판단했습니다.
2차 시도
기존 cache.m5.large(2vCPU)에서 cache.m5.xlarge(4vCPU)로 인스턴스 타입을 올렸습니다.
교체 전 스냅샷을 생성하고(10분 이내), 스냅샷으로부터 신규 Redis 서버를 생성했습니다(30분 이내)
이번에는 엔진 지표도 함께 볼 수 있게 모니터링 대시보드를 설정했습니다.
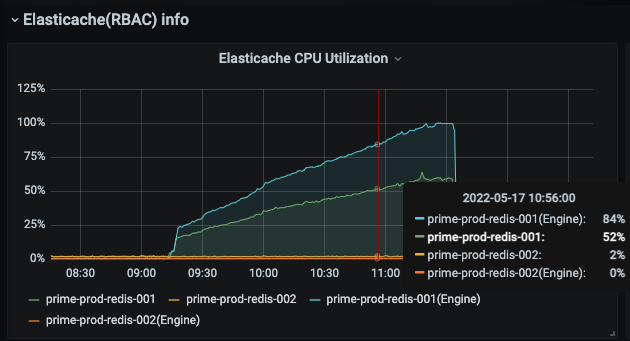
- 1차 장애 당시 신규 투입된 서버의 CPUUtilization, EngineCPUUtilization 지표
- 당시에는 EngineCPUUtilization를 보고 있지 않아서 100%까지 치고 올라가는 상황을 인지하지 못했었습니다.
- 그림에서 레디스 서버가 두 대인 것을 확인할 수 있는데, 두 대가 클러스터로 묶여(cluster mode 아님 주의) 한대가 장애가 날 경우를 대비하고 있습니다. 애플리케이션은 primary node만 바라보고 있습니다.
교체 시작!
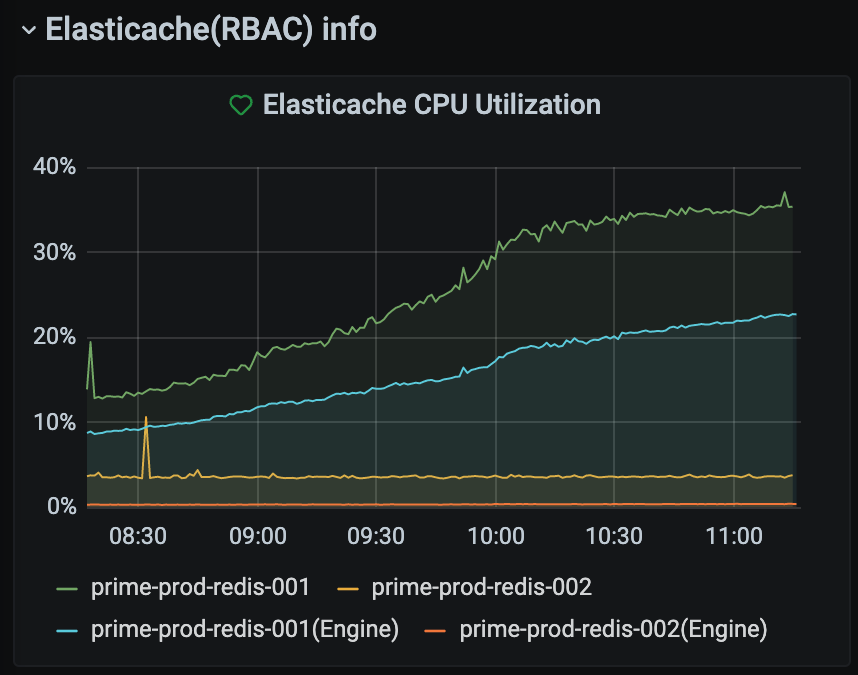
- Redis는 어쩐지 안정적인 것 같았습니다.
하지만 애플리케이션 서버 쪽 ELB Latency 지표는 200ms를 넘어가고 있었고, New Relic에서 확인한 연결 지연 시간(아래 그래프)이 심상치 않아 다시 롤백을 결정했습니다.
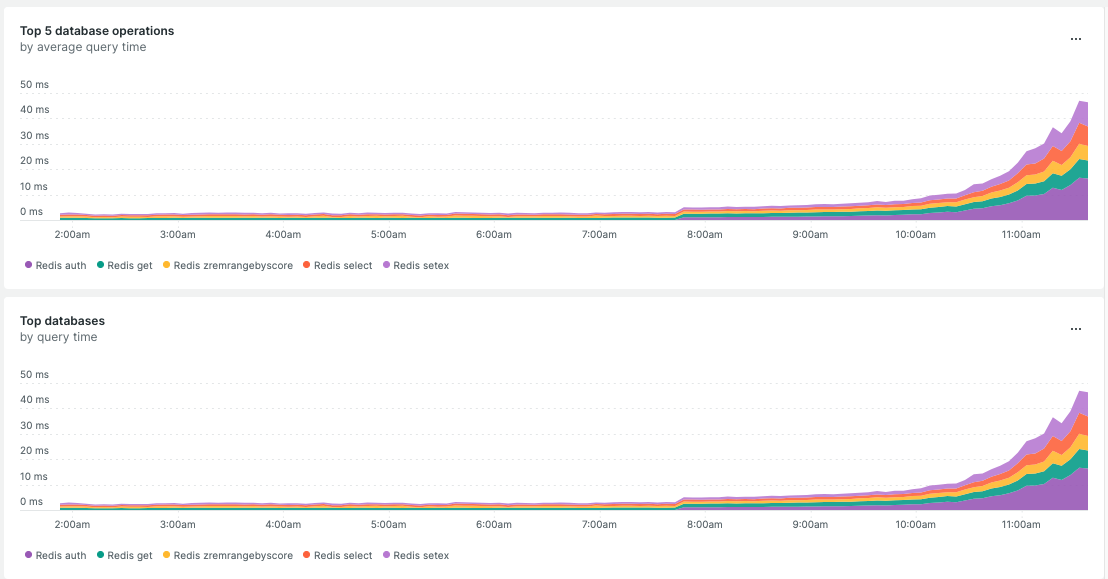
두 번의 실패 이후, 많은 반성을 하면서 ‘나는 뭘 모르고 있는지’ 찬찬히 돌아보기로 했습니다.
ElastiCache의 지표들을 이해해봅니다
EngineCPUUtilization
기존 사용하던 Redis 서버와 새로 띄운 서버는 몇 가지 지표에서 차이가 나긴 했지만, 모두 AWS Redis 지표 페이지에서 권고하는 수준 안에 있었습니다.
이 문제를 해결하기 위해 CPUUtilization와 EngineCPUUtilization는 물론이고, connection 관련 지표에 집중해서 모니터링하기로 했습니다.
첫 번째 장애 때의 그래프를 다시 가져와 봅니다.
CPUUtilization은 EngineCPUUtilization보다 낮았습니다.
CPUUtilization은 Redis 엔진(EngineCPUUtilization으로 표현)의 동작에 백그라운드 프로세스의 비용도 포함하기 때문에 이 값이 EngineCPUUtilization보다 낮은 게 이상하다고 생각했습니다.
Amazon ElastiCache for Redis 사용 설명서 > 어떤 지표를 모니터링해야 합니까? 문서를 보면, vCPU를 고려해서 알림 기준을 세워야 한다고 나와 있습니다.
일반적으로, 사용 가능한 CPU의 90%로 임계값을 설정하는 것이 좋습니다. Redis는 단일 스레드이기 때문에 실제 임계값은 노드 총 용량의 일부로 계산해야 합니다. 2개의 코어가 있는 노드 유형을 사용하는 경우를 예로 들어보겠습니다. 이 경우 CPUUtilization의 임계값은 90/2 또는 45%입니다.
당시 인스턴스 타입이 cache.m5.large였기 때문에 vCPU는 2개입니다.
위 그래프에서 CPUUtilization이 15% -> 60% 올라가는 것을 봤다면, 실제로는 30% ~ 100%구나라고 인지했어야 한다는 말입니다.
Amazon ElastiCache for Redis 사용 설명서 > Redis 지표에서의 설명에도 vCPU 2개까지의 소규모 호스트에선 CPUUtilization으로 보는 것이 더 낫다고 하는군요.
Redis 엔진 스레드의 CPU 사용률을 제공합니다. Redis는 단일 스레드이므로 이 지표를 사용하여 Redis 프로세스 자체의 로드를 분석할 수 있습니다. EngineCPUUtilization 지표는 Redis 프로세스에 대한 보다 정확한 정보를 제공합니다. 이 지표를 CPUUtilization 지표와 함께 사용할 수 있습니다. CPUUtilization은 다른 운영 체제 및 관리 프로세스를 포함하여 전체적인 서버 인스턴스의 CPU 사용률을 표시합니다. 4개 이상의 vCPU를 포함하는 대규모 노드 유형에는 EngineCPUUtilization 지표를 사용하여 조정 임계값을 모니터링하고 설정하세요.
ElastiCache 호스트에서는 백그라운드 프로세스가 관리형 데이터베이스 환경을 제공하기 위해 호스트를 모니터링합니다. 이러한 백그라운드 프로세스는 CPU 워크로드의 상당 부분을 차지할 수 있습니다. vCPU가 2개 이상(2를 초과하는)인 대규모 호스트에서는 이 점이 중요하지 않습니다. 하지만 vCPU가 2개 이하인 소규모 호스트에 영향을 줄 수 있습니다. EngineCPUUtilization 지표만 모니터링하는 경우 호스트가 Redis의 높은 CPU 사용률과 백그라운드 모니터링 프로세스의 높은 CPU 사용률로 오버로드되는 상황을 인식하지 못합니다. 따라서 vCPU가 2개 이하인 호스트의 CPUUtilization 지표를 모니터링하는 것이 좋습니다.
이 내용은 Amazon ElastiCache for Redis 사용 설명서 > 문제 해결(Troubleshooting) 문서에서도 언급됩니다.
CPU 사용량: Redis는 다중 스레드 애플리케이션입니다. 그러나 각 명령의 실행은 단일(주) 스레드에서 발생합니다. 이러한 이유로 ElastiCache는 CPUUtilization 및 EngineCPUUtilization 지표를 제공합니다. EngineCPUUtilization은 Redis 프로세스 전용 CPU 사용률을 제공하고 CPUUtilization은 모든 vCPU에 대한 사용량을 제공합니다. 두 개 이상의 vCPU가 있는 노드는 대개 CPUUtilization 및 EngineCPUUtilization의 값이 서로 다르며, 일반적으로 두 번째 값이 더 큽니다.
여기서 일반적으로 두번째 값이 더 크다고 했는데, 두번째 Redis 서버 교체 당시의 지표를 다시 가져와 볼까요?
이때는 EngineCPUUtilization 지표가 계속 낮았습니다. 이 현상에 대해 AWS 측에 문의를 해봤는데,
CPUUtilization = Redis 사용 CPU(EngineCPUUtilization) + others (Redis 외 프로세스) 사용 CPU로 이해하면 될 듯합니다.
즉, 해당 시점에는 Redis 서비스보다 others 서비스(예를 들면, 스냅샷으로 생성 이후 스토리지 최적화를 위한 작업 ?)에 CPU가 쓰이고 있었다고 봐야 할 거 같습니다.
문서에서 일반적으로 EngineCPUUtilization이 높다는 것은 해당 서버가 Redis 용이니까 일반적으로 그렇다는 의미로 보입니다.
화면에서 보이는 CPUUtilization 지표의 피크는 35%이고 이때도 일시 연결 오류가 발생했습니다. 그렇다면 어느 시점에 위험하다고 판단해야 했을까요?
이 당시 서버는 cache.m5.xlarge(4vCPU)이기 때문에, CPUUtilization 지표의 임계값을 90/4 즉, 20% 선으로 설정하고 20%가 넘으면 위험하다고 판단했어야 했을지도 모릅니다. AWS 측의 답변도,
네 , CPUUtilization 을 기준으로 본다면 22.5 % 를 임계값으로 계산해 볼 수 있겠습니다. Redis 가 단일 Thread 로 처리되므로 단일 CPU Core 가 90% 이상 사용되지 않는 것을 임계값으로 보라는 의미로 이해됩니다.
단, 4vCPU 이상의 대규모 노드 유형에는 Redis 엔진 코어 대한 사용률을 보고하는 EngineCPUUtilization 지표를 사용할 수 있습니다. 현재 사용하시는 인스턴스 유형 상 EngineCPUUtilization 으로 CPU 부하상황을 판단하는 것이 맞을 것 같습니다.
4vCPU의 대규모 노드라서 완전한 설명이 되는 건 아니지만, 아래와 같이 분석해볼 수 있겠습니다.
- 당시 redis 자체의 부하는 높지 않았다(EngineCPUUtilization 23%)
- redis 이외의 프로세스에서 높은 CPU를 사용하고 있었고(22.5%를 초과) 부하의 원인이 되었다.
Amazon ElastiCache for Redis 사용 설명서 > 어떤 지표를 모니터링해야 합니까?에서 언급된 Redis 모니터링에 관한 글도 Redis 지표를 이해하는 데 많은 도움이 됩니다.
- 여기서는 신규 커넥션이 늘어날수록 CPUUtilization 지표가 높아질 수 있다고 (가볍게) 언급이 되어있습니다.
신규 커넥션의 수 혹은 많은 커넥션 자체가 Redis 서버의 CPU 사용량을 늘리고, 이것이 장애로까지 이어졌을 거라 가정하고 개선 계획을 짜보았습니다.
개선 과정은 다음 글로 이어집니다.