모호한 앰퍼샌드(&, ampersand)
Update: ‘모호한 앰퍼샌드‘ 원작자에게 허락을 구해 해당 글의 번역본을 추가함.
개발하면서 누구나 한번쯤은 궁금해하지만, 아무도 정확히 알려주지 않는 모호한 앰퍼샌드에 대해 얕게 한번 파보았습니다.
현상
공고 관리자 페이지에서 reg_mem_type이라는 변수를 검색할 수 있는 옵션을 추가했더니, 페이징 영역을 클릭하면 계속 오류가 발생했다.
®이라는 특수문자가 전송되는 것을 보고 페이징쪽 소스를 보니
소스보기로는 이상이 없어보이나 개발자도구로는 ®가 찍히는 것을 확인.
원인
일부 html entity는 세미콜론이 없어도 전환이 가능하다는 것을 알게 됐다.
예를 들어,
<a href="test?test=test®=aa®ion=bb®_ion=cc"> |
와 같은 태그는 화면에는
test?test=test®=aa®ion=bb®_ion=cc
처럼 보이고, 개발자 도구에서 보면
test?test=test®=aa®ion=bb®_ion=cc
처럼 보인다.
이는 화면에 보여줄 때는 ®가 세미콜론이 없어도 마크로 변환해줄 수 있기 때문이며,
이게 attribute의 값으로 들어갈 때는 변환이 되지 않는다.
다만, ®_ion 처럼 ® 다음에 특수문자나 공백 등이 올 경우, 이는 ®마크로 변환이 된다.
세미콜론 없어도 변환해주는 경우
세미콜론이 없어도 마크로 변환해주는 경우가 어디에 정의되어 있는지를 잘 모르겠다.
이런 현상에 관한 질문을 좀 찾아봤다.
여기서는 named-character-references를 예로 들며, 세미콜론이 없어도 되는 문자 참조를 아래와 같이 정의한다.
AElig, AMP, Aacute, Acirc, Agrave, Aring, Atilde, Auml, COPY, Ccedil, ETH, Eacute, Ecirc, Egrave, Euml, GT, Iacute, Icirc, Igrave, Iuml, LT, Ntilde, Oacute, Ocirc, Ograve, Oslash, Otilde, Ouml, QUOT, REG, THORN, Uacute, Ucirc, Ugrave, Uuml, Yacute, aacute, acirc, acute, aelig, agrave, amp, aring, atilde, auml, brvbar, ccedil, cedil, cent, copy, curren, deg, divide, eacute, ecirc, egrave, eth, euml, frac12, frac14, frac34, gt, iacute, icirc, iexcl, igrave, iquest, iuml, laquo, lt, macr, micro, middot, nbsp, not, ntilde, oacute, ocirc, ograve, ordf, ordm, oslash, otilde, ouml, para, plusmn, pound, quot, raquo, reg, sect, shy, sup1, sup2, sup3, szlig, thorn, times, uacute, ucirc, ugrave, uml, uuml, yacute, yen, yuml
그런데 위에 언급한 named-character-references에서의 리스트와는 꽤 다르다.
예를 들어, 이 references에서 정의된 ycirc는 &ycirc_라고 해도 attribute에서 변환되지 않는다.
아직 브라우저가 구현을 안 한 것인지, HTML4 버전 때 정의된 것 만 세미콜론으로 안 끝나도 되는지는 잘 모르겠다.
아직 정확한 근거를 못 찾았는데, 누가 좀 알려줬으면 좋겠다.
정 궁금하면 더 찾아봤을텐데, 정확한 리스트를 안다고 달라질 게 없기 때문에 해결책으로 넘어간다.
해결 in PHP
페이징 링크에 들어가는 부분
$queryString = ‘&’ . http_build_query($params, ‘’, ‘&’) ;
와 같은 소스를
$queryString = ‘&’ . http_build_query($params, ‘’, ‘&’) ;
이와 같이 &만을 escape 처리함.
모호한 앰퍼샌드
아래는 이 현상을 제대로 이해하기 위해 모호한 앰퍼샌드에 관한 글을 번역한 것이다.
원문 : https://mathiasbynens.be/notes/ambiguous-ampersands
각 용어는 아래와 같이 번역함(clearboth에서 번역한 문서 참고해서 맞춤)
- Ambiguous : 모호한
- 모호한이라는 뜻으로 주로 쓰이는 것 같고, 여러 뜻으로 해석할 수 있는..이라는 의미도 될 수 있음
- named character : 명명된 문자
Character references in HTML
HTML안에서의 문자 참조
Before explaining what ambiguous ampersands are, let’s talk about character references.
모호한 앰퍼샌드가 뭔지 설명하기 전에 문자 참조에 대해 이야기 해보자
There are different kinds of character references. The HTML 4.01 spec divides them in two groups, but really there are three:
문자 참조에는 여러가지 종류가 있다. HTML4.01 스펙에는 두 개의 그룹으로 나누었지만, 사실 세가지가 있다.
- decimal numeric character references, e.g. ©
- 정수 문자 참조
- hexadecimal numeric character references, e.g. ©
- 16진수 문자 참조
- named character references, e.g. ©
- 명명된 문자 참조
Character references should always start with a U+0026 AMPERSAND character (&) and end with a U+003B SEMICOLON character (;).
문자 참조는 &로 시작하고 ;로 끝나야 한다.
Fun fact: the list of named character references in the HTML spec includes & and &, but also & and & (without the trailing semicolon). The same goes for a few other entities. This is done for backwards-compatibility reasons. This way, the spec dictates that foo & bar should be rendered as “foo & bar”, even though it’s invalid markup (because of the missing trailing semicolon). More on this in a minute…
재밌는 사실은: HTML 스펙에서 명명된 문자 참조는 &와 &를 포함하는데, 세미콜론(;)이 뒤에 붙지 않은 &와 &도 있다는 것이다. 다른 일부 엔티티도 마찬가지이다. 이건 하위 호환성을 때문에 이렇게 됐다. 이 방식으로, (세미콜론이 빠져있으면) 유효하지 않은 마크업임에도 불구하고, 스펙에선 “foo & bar”를 “foo & bar”로 랜더할 수 있게 지시하고 있다. 조금 이따가 다시 다루겠다.
In this post, we’ll take a closer look at what happens if there’s an unencoded ampersand that’s not part of a character reference in your HTML code. Is it valid? Is it invalid? And what do “ambiguous ampersands” have to do with all this?
이 포스트에선, HTML안에 지정된 문자 참조의 일부가 아니면서 인코드도 안 된 앰퍼샌드가 있을 때 어떤 일이 벌어지는 지 좀 더 자세히 살펴볼 것이다. 그게 유효한 문법인가? 아니면 유효하지 않은가? 모호한 앰퍼샌드는 이 모든 것과 어떤 관계가 있는가?
Unencoded ampersands in HTML4
인코딩되지 않은 앰퍼샌드
The HTML 4.01 spec mentions this:
HTML 4.01 스펙에서 이를 언급하기를:
The URI that is constructed when a form is submitted may be used as an anchor-style link (e.g., the href attribute for the <a> element). Unfortunately, the use of the & character to separate form fields interacts with its use in SGML attribute values to delimit character entity references. For example, to use the URI http://host/?x=1&y=2 as a linking URI, it must be written as <a href=”http://host/?x=1&y=2”> or <a href=”http://host/?x=1&y=2”>.
Form 전송 시 만들어지는 URI는 anchor 스타일 링크(예를 들어 a 엘리먼트의 href attribute)를 사용하게 된다. 불행히도, 폼 필드를 구분지으려고 &를 사용하는 것은, 문자 엔티티 참조를 위한 SGML(역주: HTML, XML등의 부모뻘 되는 언어) attribute 안에서 사용하는 것과 상호작용을 하게된다. 예를 들어, 링크를 위한 http://host/?x=1&y=2 이라는 URI는, 반드시 <a href=”http://host/?x=1&y=2”> 혹은 <a href=”http://host/?x=1&y=2”> 으로 쓰여야 한다.
This means you can’t just copy-paste URLs into your HTML4 document if you want it to be valid — you’ll have to encode any ampersand characters first.
이 말은 당신이 HTML4 문서에 URL을 단순히 복사-붙여넣기를 해서만은 유효하진 않을 거라는 의미이다 - 앰퍼샌드를 인코딩 해야할 거다.
Ambiguous ampersands in HTML5
HTML5에서의 모호한 앰퍼샌드
In HTML5, the first definition for ambiguous ampersands was added:
HTML5에서 모호한 ampersand에 대한 정의가 처음으로 추가됐다.
An ambiguous ampersand is a U+0026 AMPERSAND (&) character that is not the last character in the file, that is not followed by a space character, that is not followed by a start tag that has not been omitted, and that is not followed by another U+0026 AMPERSAND (&) character.
모호한 앰퍼샌드는 파일의 마지막 문자가 아니며, 공백 문자가 뒤이어 나오지 않고, 생략되지 않은 시작 태그가 뒤에 오지 않고 다른 앰퍼샌드 문자가 뒤따르지 않는다.
Ambiguous ampersands are non-conforming (invalid); unambiguous ampersands are generally conforming (valid). (As mentioned before: ampersands that are part of a named character reference that doesn’t end with a semicolon are unambiguous, but still invalid.)
모호한 앰퍼샌드는 …(역주: 번역하기 어려워 생략)…(이전에 언급한 것처럼: 세미콜론으로 끝나지 않는 명명된 문자 참조의 일부로써 앰퍼샌드는 모호하진 않지만, 아직 유효하진 않다.
In other words, if an unencoded ampersand is followed by EOF, a space character, <, or &, it’s perfectly valid.
다시 말해, 인코드 안 된 앰퍼샌드 뒤로 EOF, 공백문자, <, &가 있다면 이건 완전히 유효하다.
According to this definition, the ampersands in this example are all ambiguous, and thus invalid:
이 정의에 의하면, 아래 예시에서 모든 앰퍼샌드는 모호하고, 그러므로 유효하지 않다.
<a href="https://example.com/?x=1&y=2";>foo</a> |
However, this is valid HTML:
그러나, 이건 또 유효한 HTML이다
foo & bar |
Later the spec was changed, and the HTML spec now defines ambiguous ampersands as follows:
나중에 스펙은 수정되고 현재 HTML 스펙은 아래와 같이 정의되어 있다.
An ambiguous ampersand is a U+0026 AMPERSAND character (&) that is followed by one or more characters in the range U+0030 DIGIT ZERO (0) to U+0039 DIGIT NINE (9), U+0061 LATIN SMALL LETTER A to U+007A LATIN SMALL LETTER Z, and U+0041 LATIN CAPITAL LETTER A to U+005A LATIN CAPITAL LETTER Z, followed by a U+003B SEMICOLON character (;), where these characters do not match any of the names given in the named character references section.
모호한 앰퍼샌드는 하나 이상의 0~9 숫자, 대/소문자 라틴 문자와 세미콜론으로 이어지는 엠퍼샌드를 의미하고, 이 문자들은 명명된 문자 참조 영역에 있는 이름에 매칭되지 않는다.
This definition is probably easier to grok as a regular expression: a string contains an ambiguous ampersand if it matches /&([0-9a-zA-Z]+;)/ and if the first back-reference ($1) is not a known character reference.
이 정의는 아마 정규식으로 더 이해하기 쉬울 것 같다. 앰퍼샌드가 포함된 문자열이 /&([0-9a-zA-Z]+;)/ 에 매치되고, back-reference 된 값(역주: 정규식에서 괄호안에 매칭되는 값)이 알려진 문자 참조가 아니어야 한다.
The ampersands in this example are all ambiguous, and thus invalid:
아래 앰퍼샌드는 모두 모호하다. 따라서 유효한 문법이 아니다.
&123; |
However, all these are unambiguous:
그러나 아래는 모두 명확하다.
foo & bar |
…even the ones that were invalid as per the old definition, are now valid:
…예전의 정의로는 유효하진 않지만, 현재 유효한 것은:
<a href="http://example.com/?x=1&y=2";>foo</a> |
With the new definition, this is perfectly valid HTML — even though no HTML validator I know of recognizes this yet.
새로운 정의에 의해서는, 완벽하게 유효한 HTML이다 - HTML 유효성 검사기가 아직 이걸 모른다 하더라도 말이다.
So we’ve established that not all ampersand characters require escaping in HTML. Semi-related fun fact: In most cases, there’s no need to escape the > character either. It has no special meaning (and is thus unambiguous) unless it’s part of a tag or an unquoted attribute value. For example, <p>foo > bar</p> is perfectly valid and reliable HTML.
이제 우리는 HTML안에서 모든 앰퍼샌드가 escape 될 필요는 없다는 게 확실해졌다. 크게 관련은 없지만 재밌는 사실은: > 문자도 escape할 필요가 없다는 사실이다. 따옴표 없는 attribute값이나 태그의 일부가 아닌 이상 특수한 의미가 있지는 않다(모호하지 않음). 예를 들어, <p>foo > bar</p>는 완전히 유효하며 믿을만 한 HTML이다.
The pedantic nitty-gritty
학술적인 핵심
As mentioned before, some named character references work without a trailing semicolon (e.g. &) even though it’s invalid markup. What complicates things even more is that these entities are handled differently in attribute values.
말했지만, 일부 명명된 문자 참조는 세미콜론이 뒤에 붙지 않아도(그게 유효하지 않은 마크업 문법이라도) 동작한다. 이걸 더 복잡하게 만드는 건, 이 엔티티들이 attribute 값에서는 다르게 작동한다는 사실이다.
If the character reference is being consumed as part of an attribute, and the last character matched is not a U+003B SEMICOLON character (;), and the next character is either a U+003D EQUALS SIGN character (=) or an alphanumeric ASCII character, then, for historical reasons, all the characters that were matched after the U+0026 AMPERSAND character (&) must be unconsumed, and nothing is returned. However, if this next character is in fact a U+003D EQUALS SIGN character (=), then this is a parse error, because some legacy user agents will misinterpret the markup in those cases.
만약 문자 참조가 attribute안에서 사용되고 세미콜론으로 끝나지 않으며 다음 글자가 =나 알파벳, 숫자일 경우, 관행적으로, & 이후 매칭되는 모든 문자들은 처리되지 않고 아무것도 리턴되지 않는다. 그러나 이 ‘다음 문자’가 =이라면, parse error가 발생하는데, 오래된 user agent가 오역할 수 있기 때문이다.
Take this (obviously invalid) HTML, for example:
예를 들어, 명백히 유효하지 않은 다음 HTML을 보라
<p title="foo&bar"> |
Try it out in your browser. You’ll see that the paragraph’s text content displays as “foo&bar”, while the titleattribute value is displayed as “foo&bar”.
네 브라우저에서 시도해봐라. 내용은 “foo&bar”라고 나오지만, title attribute 값은 foo&bar로 나올 것이다.
Mothereffing ambiguous ampersands
형편없는 모호한 앰퍼샌드
To summarize: there’s a difference between unencoded ampersands (sometimes valid), ambiguous ampersands (always invalid) and encoded ampersands (always valid). An unencoded ampersand is not always an ambiguous ampersand. An unambiguous ampersand can still be invalid.
요약하자면: 인코딩 안 된 앰퍼샌드(가끔 유효한), 모호한 앰퍼샌드(언제나 유효하지 않은), 그리고 인코딩된 앰퍼샌드(언제나 유효한) 사이에는 차이점이 있다. 인코딩이 안 된 앰퍼샌드가 항상 모호한 앰퍼샌드인 건 아니다. 모호하지 않은 앰퍼샌드도 여전히 유효하지 않을 수 있다.
In my opinion, this is all a bit confusing. But it doesn’t have to be! When in doubt, just encode your effin’ ampersands.
내 생각에, 이것들은 좀 헷갈린다. 하지만 그럴 필요는 없다! 의심스러우면, 망할 앰퍼샌드를 인코딩해라.
That said, if you want to find out if an HTML snippet contains any ambiguous ampersands or character references that don’t end with a semicolon (both of which are invalid), feel free to use mothereff.in/ampersands.
즉, HTML 스니펫에 모호한 앰퍼샌드나 세미콜론 (세미콜론으로 끝나지 않는 문자 참조)이 모두 포함되어 있는지 알아 보려면 (둘 다 유효하지 않음) mothereff.in/ampersands를 자유롭게 사용하기 바란다.
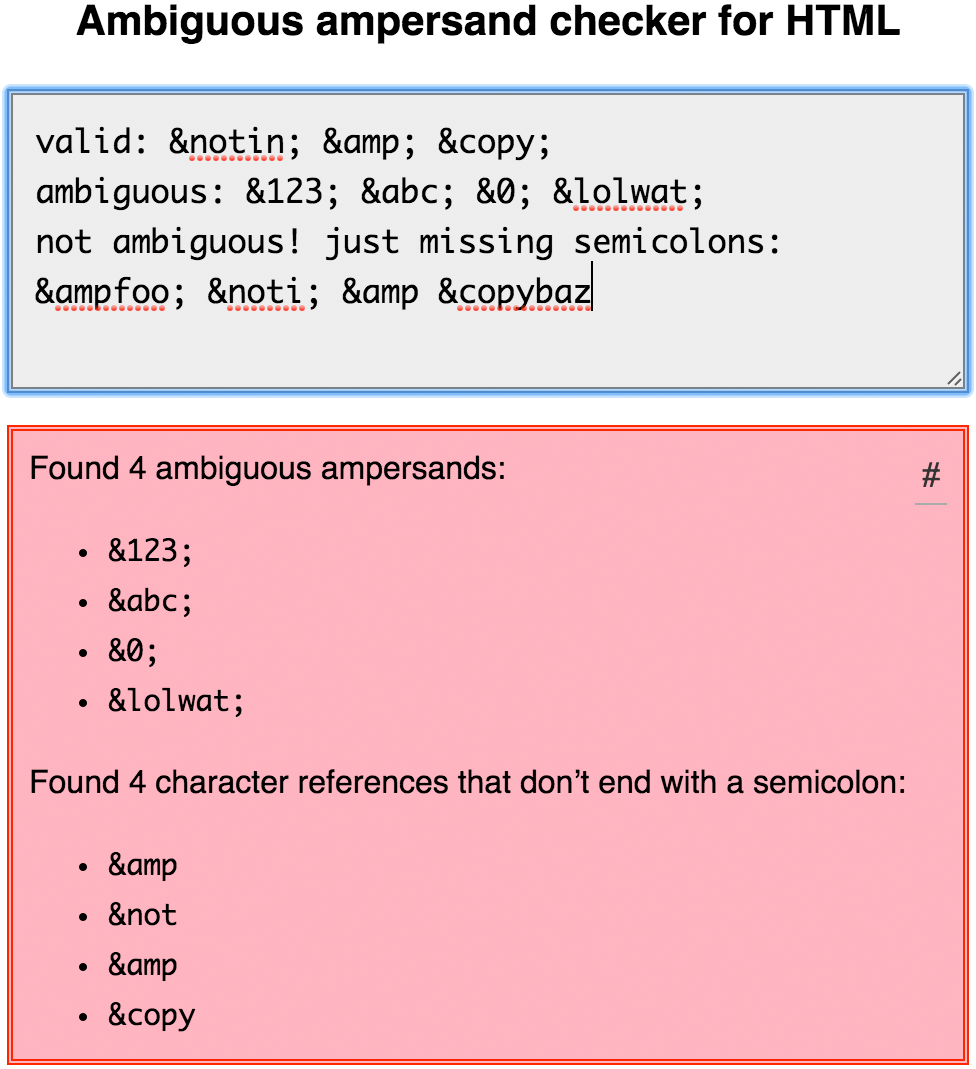
Note that this is not a complete HTML validator; it will only look for ambiguous ampersands and semicolon-free character references. (Hopefully, bug #841 will be fixed soon, so we can just rely on validator.nu instead.)
Understanding what ambiguous ampersands are and how they work is especially important for library authors wishing to deal with HTML entities. Not accounting for these edge cases might result in XSS or other security vulnerabilities in your code.